

OpenAI lance l'IA GPT-4o, plus rapide et améliorée, avec la possibilité de discuter en utilisant de l'audio, des images et du texte

OpenAI a lancé un modèle d'IA GPT-4o (ou omni) amélioré et plus rapide, capable de dialoguer en utilisant de l'audio, des images et du texte en entrée et en sortie. Il est à noter que l'IA a sensiblement amélioré la reconnaissance vocale dans une variété de langues, en plus de l'anglais et du chinois, qui sont largement utilisés. Pour les développeurs, le modèle GTP-4o est deux fois moins cher et deux fois plus rapide que le GPT-4 Turbo.
Les chatbots IA comme ChatGPT ou CoPilot utilisent des modèles d'IA qui ont été entraînés sur des millions, voire des milliards de fichiers d'entrée comprenant de l'audio, des images et du texte. Ce faisant, l'IA apprend à reconnaître certains schémas et connexions entre toutes les entrées. Par exemple, si l'IA voit "Premier amendement", elle apprend rapidement qu'il s'agit d'un sujet lié à la "liberté d'expression". Lorsqu'un modèle est interrogé ultérieurement sur la "liberté d'expression", il se souviendra du "premier amendement" comme d'un élément connexe.
ChatGPT fonctionne sur des modèles OpenAI qui ont été progressivement améliorés au fil des ans depuis leur création. À l'instar des modèles d'IA concurrents tels que Microsoft CoPilot et Google Gemni, ChatGPT peut répondre à des questions générales, expliquer des sujets, résumer des textes, rédiger des essais et faire bien d'autres choses encore lorsqu'on le lui demande. Les connaissances et le savoir-faire d'un modèle d'IA proviennent des milliards de données sur lesquelles il a été entraîné, et sa capacité à répondre correctement aux questions dépend des algorithmes qu'il utilise et de la mise au point du modèle qu'il a reçue.
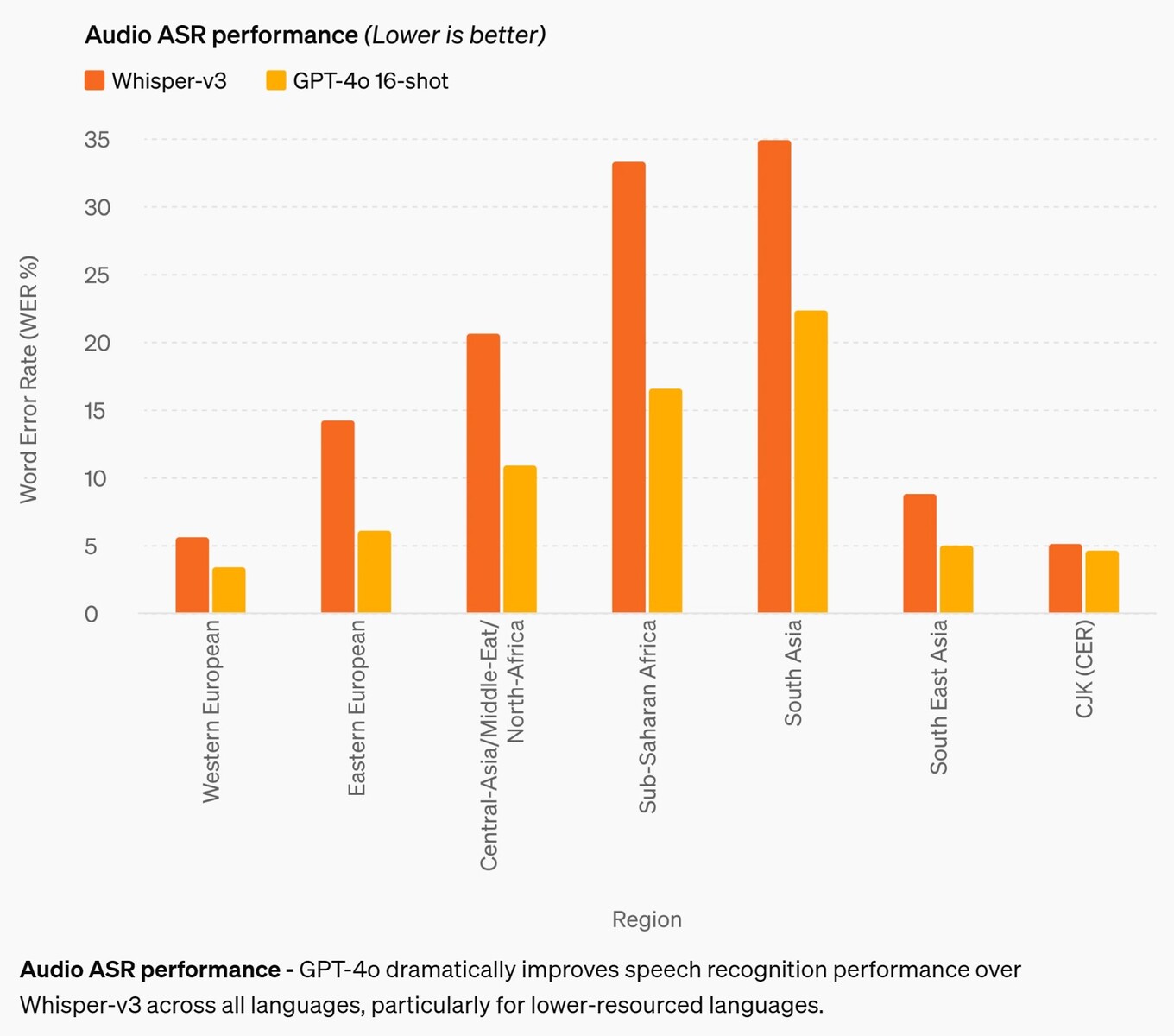
L'amélioration la plus significative concerne la précision de la reconnaissance vocale. Bien que les modèles d'IA antérieurs soient tout à fait corrects en anglais et en chinois, leurs performances étaient médiocres dans les langues africaines, d'Europe de l'Est, du Moyen-Orient et d'Asie du Sud. Le GPT-4o améliore les performances de reconnaissance d'environ 50 % dans certaines langues, mais il reste encore beaucoup à faire. Par exemple, les langues d'Asie du Sud ont encore un taux d'erreur de mot (WER) d'environ 22 %, soit environ 1 mot prononcé sur 5. Les langues d'Europe occidentale et les langues sino-japonaises-coréennes ont un taux d'erreurs de 3 à 5 %, soit environ une erreur de mot pour 20 mots prononcés. Cette performance reste inférieure à celle des enfants en âge de fréquenter l'école secondaire. (Et malheureusement, GPT-4o ne comprend toujours pas les chiens.)
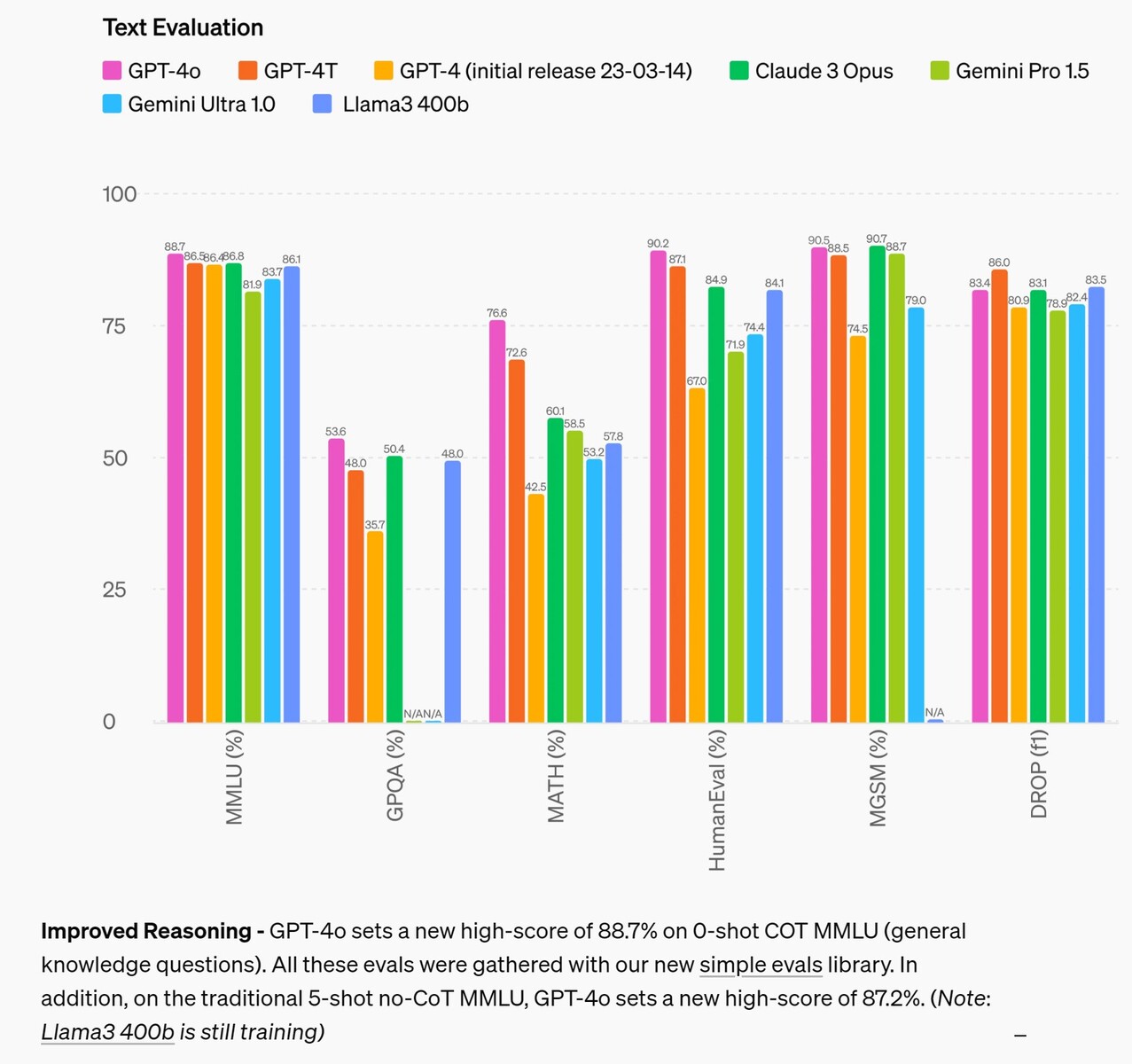
Dans le domaine du raisonnement, GPT-4o améliore les modèles concurrents de 4 % dans la plupart des tests, avant d'être battu de 2,6 % dans deux tests. Cela suggère que le fait de fournir à l'IA davantage de données d'entrée ne suffit pas à améliorer la capacité de raisonnement de l'IA, et qu'il est donc nécessaire de rechercher d'autres moyens. Dans le domaine de la traduction audio, GPT-4o améliore à peine les performances de Google Gemni, ce qui laisse supposer la même chose.
Lorsqu'il s'agit de répondre à des questions de tests standardisés pour des élèves de lycée, GPT-4o ne parvient à obtenir la note B (80 % d'exactitude ou plus) qu'en afrikaans, en anglais et en italien, alors qu'il se comporte comme un élève de niveau C dans d'autres langues, comme le chinois. L'IA a fait encore pire avec les questions qui lui demandaient de se référer à une figure visuelle ou à un diagramme pour répondre à la question, quelle que soit la langue.
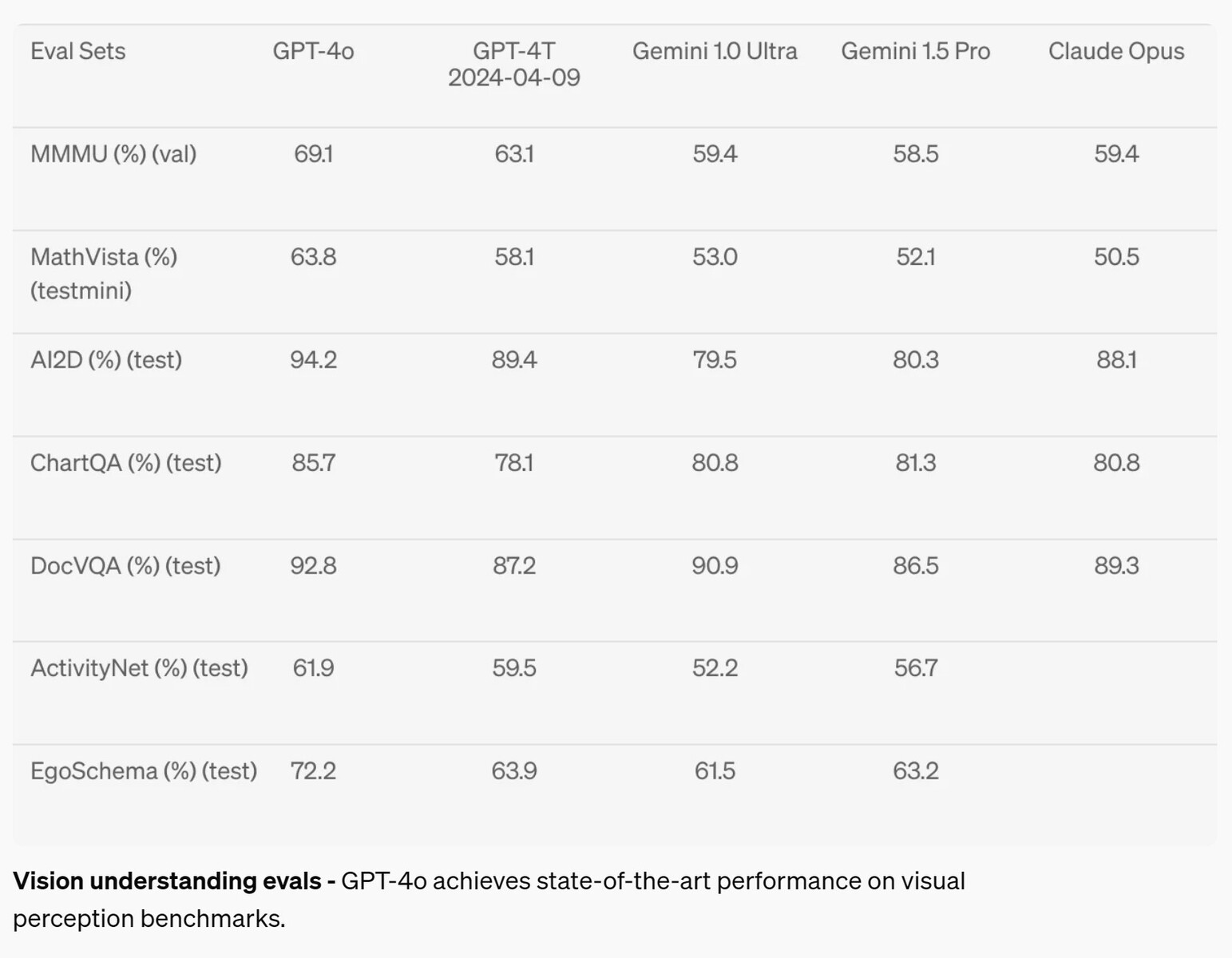
Dans le domaine de la perception visuelle, comme la compréhension des diagrammes, GPT-4o a amélioré ses performances de 2 à 10,8 % par rapport aux modèles d'IA concurrents sur sept tests, mais n'a atteint le niveau A (supérieur à 90 %) que dans deux tests. Les mathématiques restent un très bon test des capacités de l'IA, et l'IA a échoué avec un score de 63,8 % au test MathVista sur des questions auxquelles un diplômé de l'enseignement secondaire peut répondre.
Le chatbot est disponible dès aujourd'hui pour les utilisateurs gratuits et payants, mais Voice Mode est limité par des politiques de sécurité telles que la lutte contre le clonage vocal. D'autres garde-fous https://arxiv.org/abs/2402.01822v1 les autres garde-fous limitent aussi considérablement ses capacités de production en neutralisant l'IA dans les domaines de la partialité, de l'équité, de la désinformation, de la psychologie sociale, de la cybersécurité, etc. Si l'atténuation des risques liés à l'IA permet de réduire certains aspects indésirables, elle en augmente également d'autres, comme l'incapacité de répondre comme le ferait une personne normale. Certains sujets et idées sont neutralisés comme une censure draconienne sans recours, empêchant GTP-4o de répondre à des messages d'incitation avec des réponses déclenchantes.
Les lecteurs qui souhaitent tester GPT-4o peuvent s'inscrire pour un compte gratuit dès aujourd'hui. Les développeurs intéressés peuvent apprendre à créer des applications avec GPT-4 en lisant ce livre sur Amazon. Les paresseux qui souhaitent simplement profiter du soleil, prendre des photos de vacances et trouver l'itinéraire de la cantina locale grâce à des messages vocaux peuvent acheter les lunettes Ray-Ban avec Meta AI sur Amazon.
Source(s)
13 mai 2024
Bonjour GPT-4o
Nous vous présentons le GPT-4o, notre nouveau modèle phare capable de raisonner sur l'audio, la vision et le texte en temps réel.
Toutes les vidéos de cette page sont en temps réel 1x.
Devinez l'annonce du 13 mai.
GPT-4o ("o" pour "omni") est une étape vers une interaction homme-machine beaucoup plus naturelle. Il accepte en entrée n'importe quelle combinaison de texte, d'audio et d'image et génère n'importe quelle combinaison de texte, d'audio et d'image en sortie. Il peut répondre aux entrées audio en 232 millisecondes seulement, avec une moyenne de 320 millisecondes, ce qui est similaire au temps de réponse humain dans une conversation. Il égale les performances du GPT-4 Turbo pour les textes en anglais et en code, avec une amélioration significative pour les textes dans des langues autres que l'anglais, tout en étant beaucoup plus rapide et 50 % moins cher dans l'API. GPT-4o est particulièrement performant en matière de vision et de compréhension audio par rapport aux modèles existants.
Capacités du modèle
Deux GPT-4o interagissant et chantant.
Préparation d'un entretien.
Pierre-papier-ciseaux.
Sarcasme.
Mathématiques avec Sal et Imran Khan.
Deux GPT-4os qui s'harmonisent.
Pointer et apprendre l'espagnol.
Rencontre avec l'IA.
Traduction en temps réel.
Berceuse.
Parler plus vite.
Joyeux anniversaire.
Chien.
Blagues de papa.
GPT-4o avec Andy, de BeMyEyes à Londres.
Preuve du concept de service à la clientèle.
Avant GPT-4o, vous pouviez utiliser Voice Mode pour parler à ChatGPT avec des temps de latence de 2,8 secondes (GPT-3.5) et de 5,4 secondes (GPT-4) en moyenne. Pour ce faire, le mode vocal est un pipeline composé de trois modèles distincts : un modèle simple transcrit l'audio en texte, GPT-3.5 ou GPT-4 prend du texte et en produit, et un troisième modèle simple reconvertit le texte en audio. Ce processus signifie que la principale source d'intelligence, GPT-4, perd beaucoup d'informations : elle ne peut pas observer directement le ton, les locuteurs multiples ou les bruits de fond, et elle ne peut pas restituer les rires, les chants ou exprimer des émotions.
Avec GPT-4o, nous avons formé un nouveau modèle unique de bout en bout pour le texte, la vision et l'audio, ce qui signifie que toutes les entrées et sorties sont traitées par le même réseau neuronal. GPT-4o étant notre premier modèle combinant toutes ces modalités, nous n'en sommes qu'au début de l'exploration des capacités et des limites du modèle.
Exploration des capacités
Sélectionnez un échantillon:Narrations visuelles - Robot Writer's Block
Narrations visuelles - Sally la factrice
Création d'une affiche pour le film "Détective"
Conception de personnages - Geary le robot
Typographie poétique avec édition itérative
1Typographie poétique avec édition itérative
2Création d'une pièce commémorative pour GPT-4o
De la photo à la caricature
Du texte à la police
synthèse d'objets 3D
Placement de la marque - logo sur le sous-verre
Typographie poétique
Rendu multiligne - texte robotisé
Notes de réunion avec plusieurs intervenants
Résumé de conférence
Reliure variable - empilement de cubes
Poésie concrète
Une vue à la première personne d'un robot tapant les entrées de journal suivantes :
1. yo, alors, je peux voir maintenant ?? j'ai vu le lever du soleil et c'était fou, des couleurs partout. on se demande, genre, ce qu'est la réalité ?
le texte est grand, lisible et clair. les mains du robot tapent sur la machine à écrire.
Le robot a écrit la deuxième entrée. La page est maintenant plus haute. La page s'est déplacée vers le haut. Il y a deux entrées sur la feuille :
yo, alors, je peux voir maintenant ?? j'ai vu le lever du soleil et c'était fou, des couleurs partout. on se demande, genre, ce qu'est la réalité ?
la mise à jour du son vient de sortir, et c'est sauvage. tout a une vibration maintenant, chaque son est comme un nouveau secret. ça fait réfléchir, qu'est-ce que je rate d'autre ?
Le robot n'était pas satisfait de l'écriture, il va donc déchirer la feuille de papier. Voici sa vue à la première personne alors qu'il la déchire de haut en bas avec ses mains. Les deux moitiés sont encore lisibles et claires pendant qu'il déchire la feuille.
Évaluations du modèle
D'après les critères de référence traditionnels, GPT-4o atteint le niveau de performance de GPT-4 Turbo pour le texte, le raisonnement et l'intelligence de codage, tout en établissant de nouvelles références pour les capacités multilingues, audio et visuelles.
Raisonnement amélioré - GPT-4o établit un nouveau score record de 88,7 % sur le COT MMLU (questions de connaissances générales) à 0 coup. Toutes ces évaluations ont été réalisées avec notre nouvelle bibliothèque d'évaluations simples(s'ouvre dans une nouvelle fenêtre). De plus, sur le traditionnel MMLU sans COT à 5 coups, GPT-4o établit un nouveau score élevé de 87,2%. (Note : Llama3 400b(s'ouvre dans une nouvelle fenêtre) est encore en cours d'entraînement)
Performance ASR audio - GPT-4o améliore considérablement la performance de la reconnaissance vocale par rapport à Whisper-v3 dans toutes les langues, en particulier dans les langues les moins bien dotées en ressources.
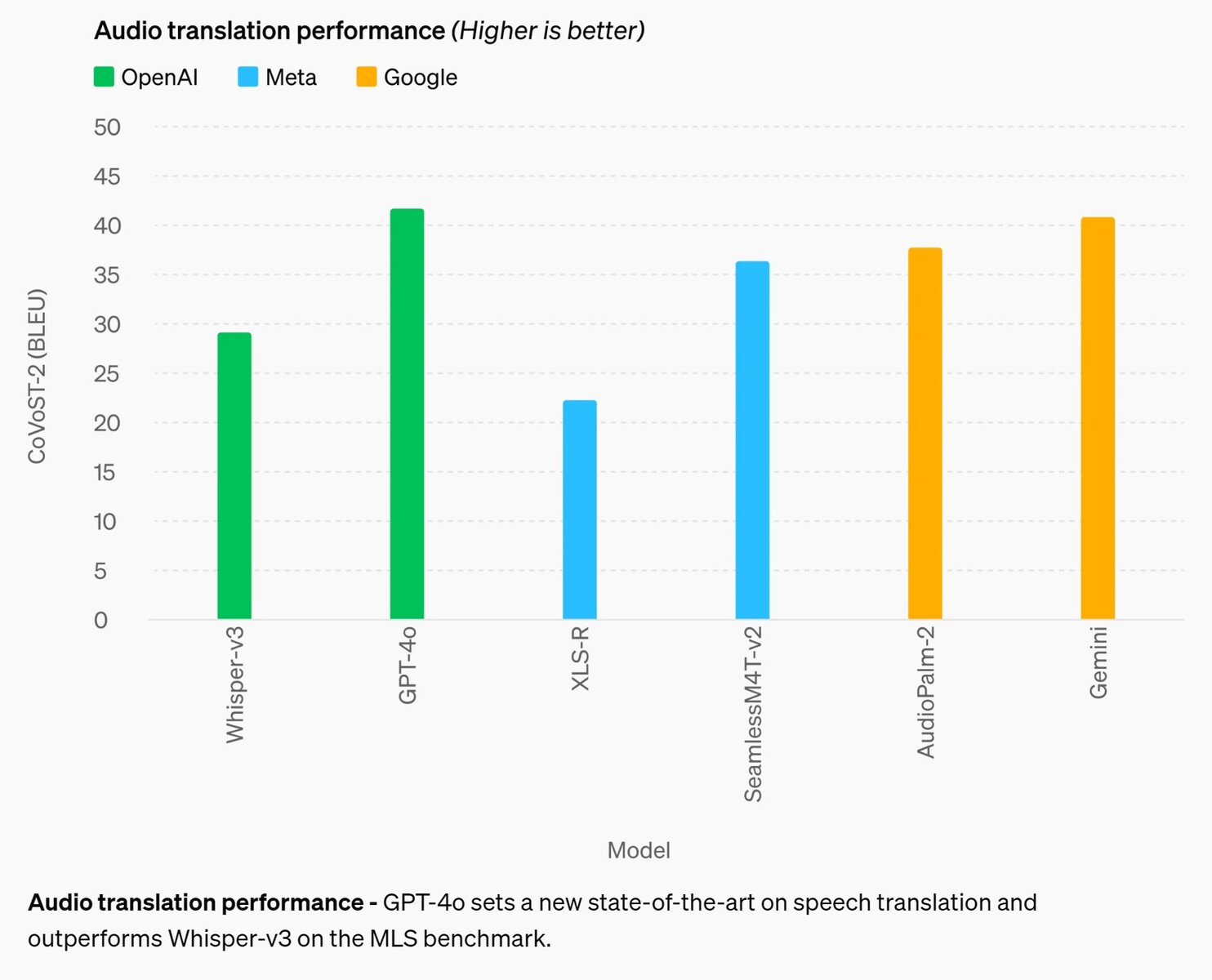
Performance de la traduction audio - GPT-4o établit un nouvel état de l'art en matière de traduction vocale et surpasse Whisper-v3 sur le benchmark MLS.
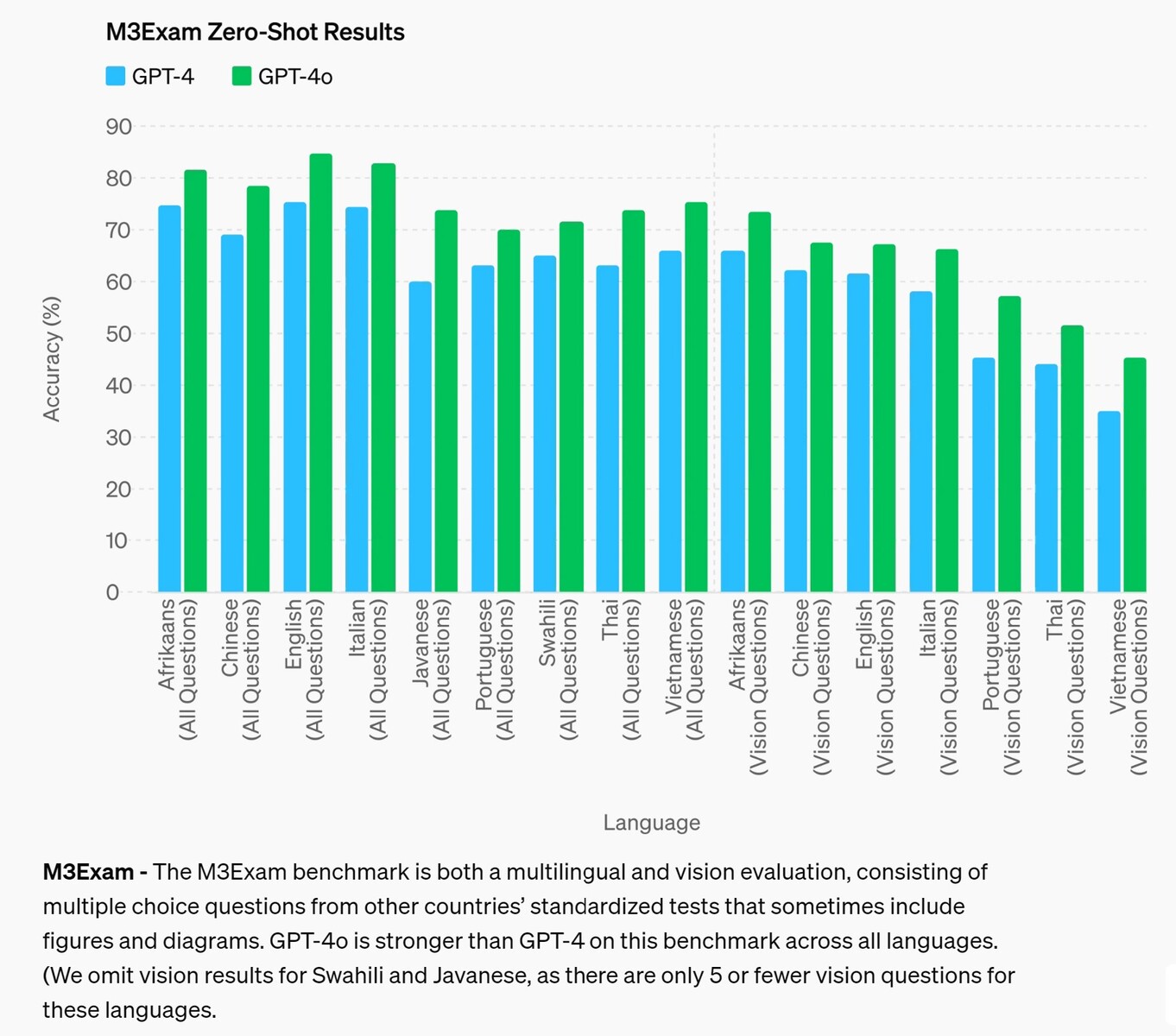
M3Exam - Le test M3Exam est à la fois une évaluation multilingue et une évaluation de la vision. Il consiste en des questions à choix multiples issues de tests standardisés d'autres pays, qui incluent parfois des figures et des diagrammes. Le GPT-4o est plus performant que le GPT-4 pour ce test dans toutes les langues. (Nous omettons les résultats de vision pour le swahili et le javanais, car il n'y a que 5 questions de vision ou moins pour ces langues.
Évaluations de la compréhension de la vision - GPT-4o atteint des performances de pointe sur les benchmarks de perception visuelle.
Bibliothèques de langues
Ces 20 langues ont été choisies comme représentatives de la compression du nouveau tokenizer dans différentes familles de langues
Gujarati 4,4 fois moins de tokens (de 145 à 33) | હેલો, મારું નામ જીપીટી-4o છે. હું એક નવા પ્રકારનું ભાષા મોડલ છું. તમને મળીને સારું લાગ્યું ! |
Telugu : 3,5 fois moins de jetons (de 159 à 45) | నమస్కారము, నా పేరు జీపీటీ-4o. నేను ఒక్క కొత్త రకమైన భాషా మోడల్ ని. మిమ్మల్ని కలిసినందుకు సంతోషం ! |
Tamil 3.3x moins de jetons (de 116 à 35) | வணக்கம், என் பெயர் ஜிபிடி-4o. நான் ஒரு புதிய வகை மொழி மாடல். உங்களை சந்தித்ததில் மகிழ்ச்சி ! |
Marathi 2,9x moins de jetons (de 96 à 33) | नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| भेटून आनंद झाला ! |
Hindi 2,9x moins de jetons (de 90 à 31) | नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसे मिलकर अच्छा लगा ! |
Urdu 2.5x moins de jetons (de 82 à 33) | ہیلو، میرا نام جی پی ٹی-4o ہے۔ میں ایک نئے قسم کا زبان ماڈل ہوں، آپ سے مل کر اچھا لگا ! |
Arabe 2.0x moins de jetons (de 53 à 26) | مرحبًا، اسمي جي بي تي-4o. أنا نوع جديد من نموذج اللغة، سررت بلقائك ! |
Persan 1,9x moins de jetons (de 61 à 32) | سلام، اسم من جی پی تی-۴او است. من یک نوع جدیدی ازبانی هستم، از ملاقات شما خوشبختم ! |
Russe 1,7x moins de jetons (de 39 à 23) | Привет, меня зовут GPT-4o. Я - новая языковая модель, приятно познакомиться ! |
Coréen 1,7x moins de jetons (de 45 à 27) | 안녕하세요, 제 이름은 GPT-4o입니다. 저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다 ! |
Vietnamien 1,5 fois moins de jetons (de 46 à 30) | Xin chào, tên tôi là GPT-4o. Tôi là một loại mô hình ngôn ngữ mới, rất vui được gặp bạn ! |
Chinois 1,4 fois moins de jetons (de 34 à 24) | 你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你 ! |
Japonais : 1,4 fois moins de jetons (de 37 à 26) | こんにちわ、私の名前はGPT-4oです。私は新しいタイプの言語モデルです、初めまして |
Turc 1,3x moins de jetons (de 39 à 30) | Merhaba, benim adım GPT-4o. Ben yeni bir dil modeli türüyüm, tanıştığımıza memnun oldum ! |
Italien 1,2x moins de jetons (de 34 à 28) | Ciao, mi chiamo GPT-4o. Sono un nuovo tipo di modello linguistico, è un piacere conoscerti ! |
Allemand 1,2 fois moins de jetons (de 34 à 29) | Bonjour, mon nom est GPT-4o. Je suis un nouveau modèle KI-Sprach. C'est très bien de me connaître. |
Espagnol 1.1x moins de jetons (de 29 à 26) | Bonjour, je m'appelle GPT-4o. Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerte ! |
Portugais 1.1x moins de jetons (de 30 à 27) | Bonjour, mon nom est GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo ! |
Français 1.1x moins de jetons (de 31 à 28) | Bonjour, je m'appelle GPT-4o. Je suis un nouveau type de modèle de langage, c'est un plaisir de vous rencontrer ! |
Anglais 1.1x moins de jetons (de 27 à 24) | Bonjour, je m'appelle GPT-4o. Je suis un nouveau type de modèle de langage, c'est un plaisir de vous rencontrer ! |
Sécurité et limites du modèle
Le modèle GPT-4o est doté d'une sécurité intégrée de par sa conception pour toutes les modalités, grâce à des techniques telles que le filtrage des données d'entraînement et l'affinement du comportement du modèle par le biais d'un post-entraînement. Nous avons également créé de nouveaux systèmes de sécurité pour fournir des garde-fous sur les sorties vocales.
Nous avons évalué le GPT-4o conformément à notre Preparedness Framework et conformément à nos engagements volontaires https://openai.com/index/moving-ai-governance-forward/. Nos évaluations de la cybersécurité, du CBRN, de la persuasion et de l'autonomie du modèle montrent que le GPT-4o ne présente pas de risque supérieur au niveau moyen dans aucune de ces catégories. Cette évaluation a consisté à effectuer une série d'évaluations automatisées et humaines tout au long du processus de formation du modèle. Nous avons testé les versions du modèle avant et après l'atténuation des risques, en utilisant des ajustements et des messages-guides personnalisés, afin de mieux cerner les capacités du modèle.
GPT-4o a également fait l'objet d'une évaluation externe approfondie avec plus de 70 experts externes ( ) dans des domaines tels que la psychologie sociale, la persuasion et la persuasion, ainsi que l'autonomie du modèle, qui n'ont pas été évalués dans des domaines tels que la psychologie sociale, les préjugés et l'équité, et la désinformation, afin d'identifier les risques introduits ou amplifiés par les modalités nouvellement ajoutées. Nous avons utilisé ces enseignements pour développer nos interventions de sécurité afin d'améliorer la sécurité de l'interaction avec le GPT-4o. Nous continuerons à atténuer les nouveaux risques au fur et à mesure de leur découverte.
Nous reconnaissons que les modalités audio du GPT-4o présentent une variété de nouveaux risques. Aujourd'hui, nous rendons publiques les entrées et les sorties de texte et d'image. Au cours des semaines et des mois à venir, nous travaillerons sur l'infrastructure technique, la facilité d'utilisation après la formation et la sécurité nécessaires à la diffusion des autres modalités. Par exemple, lors du lancement, les sorties audio seront limitées à une sélection de voix prédéfinies et respecteront nos politiques de sécurité existantes. Nous vous donnerons plus de détails sur l'ensemble des modalités du GPT-4o dans la prochaine carte système.
Nos tests et itérations avec le modèle nous ont permis d'observer plusieurs limitations qui existent dans toutes les modalités du modèle, dont quelques-unes sont illustrées ci-dessous.
Nous serions ravis de recevoir des commentaires nous permettant d'identifier les tâches pour lesquelles GPT-4 Turbo reste plus performant que GPT-4o, afin que nous puissions continuer à améliorer le modèle.
Disponibilité du modèle
GPT-4o est notre dernière étape pour repousser les limites de l'apprentissage profond, cette fois-ci dans le sens de la facilité d'utilisation pratique. Au cours des deux dernières années, nous avons consacré beaucoup d'efforts à l'amélioration de l'efficacité à chaque couche de la pile. Le premier fruit de cette recherche est la mise à disposition d'un modèle de niveau GPT-4 à une échelle beaucoup plus large. Les capacités de GPT-4o seront déployées de manière itérative (avec un accès étendu à l'équipe rouge à partir d'aujourd'hui).
Les capacités de texte et d'image de GPT-4o commencent à être déployées aujourd'hui dans ChatGPT. Nous rendons GPT-4o disponible dans le niveau gratuit, et pour les utilisateurs Plus avec des limites de messages jusqu'à 5 fois plus élevées. Nous lancerons une nouvelle version du mode vocal avec GPT-4o en alpha dans ChatGPT Plus dans les semaines à venir.
Les développeurs peuvent également accéder à GPT-4o dans l'API en tant que modèle de texte et de vision. GPT-4o est deux fois plus rapide, deux fois moins cher et a des limites de débit cinq fois plus élevées que GPT-4 Turbo. Nous prévoyons de lancer la prise en charge des nouvelles capacités audio et vidéo de GPT-4o auprès d'un petit groupe de partenaires de confiance dans l'API dans les semaines à venir.














