

Interview | "Nos gros cœurs moyens sont meilleurs que leur armée de petits cœurs" Ben Conrad d'AMD parle de certaines des décisions de conception des APU Ryzen AI et de ce qui fait le charme de Strix Halo

AMD a été très actif au CES 2025 avec une multitude d'annonces de nouveaux matériels. Il s'agit notamment des Ryzen 9 9950X3D cPU de bureau, Ryzen 9 9955HX3D et d'autres APU de la gamme Fireun aperçu de RDNA 4les nouveaux APU Ryzen AI 300 et 200, et le fleuron de la gamme, le Ryzen AI Max Strix Halo.
En marge de l'événement, Vaidyanathan Subramaniam (VS) de Notebookcheck s'est entretenu avec Ben Conrad d'AMD, directeur de la gestion des produits pour les clients mobiles haut de gamme, pour parler des nouveaux lancements d'APU Ryzen et de ce qu'ils signifient pour AMD vis-à-vis de la concurrence, ainsi que de la direction que le marché mobile est susceptible de prendre dans les jours à venir.
TL;DR : AMD respire l'optimisme avec Strix Point et Strix Halo
Voici un bref résumé de ce que nous avons appris de notre interaction avec Ben. Vous trouverez ci-dessous l'intégralité de l'entretien :
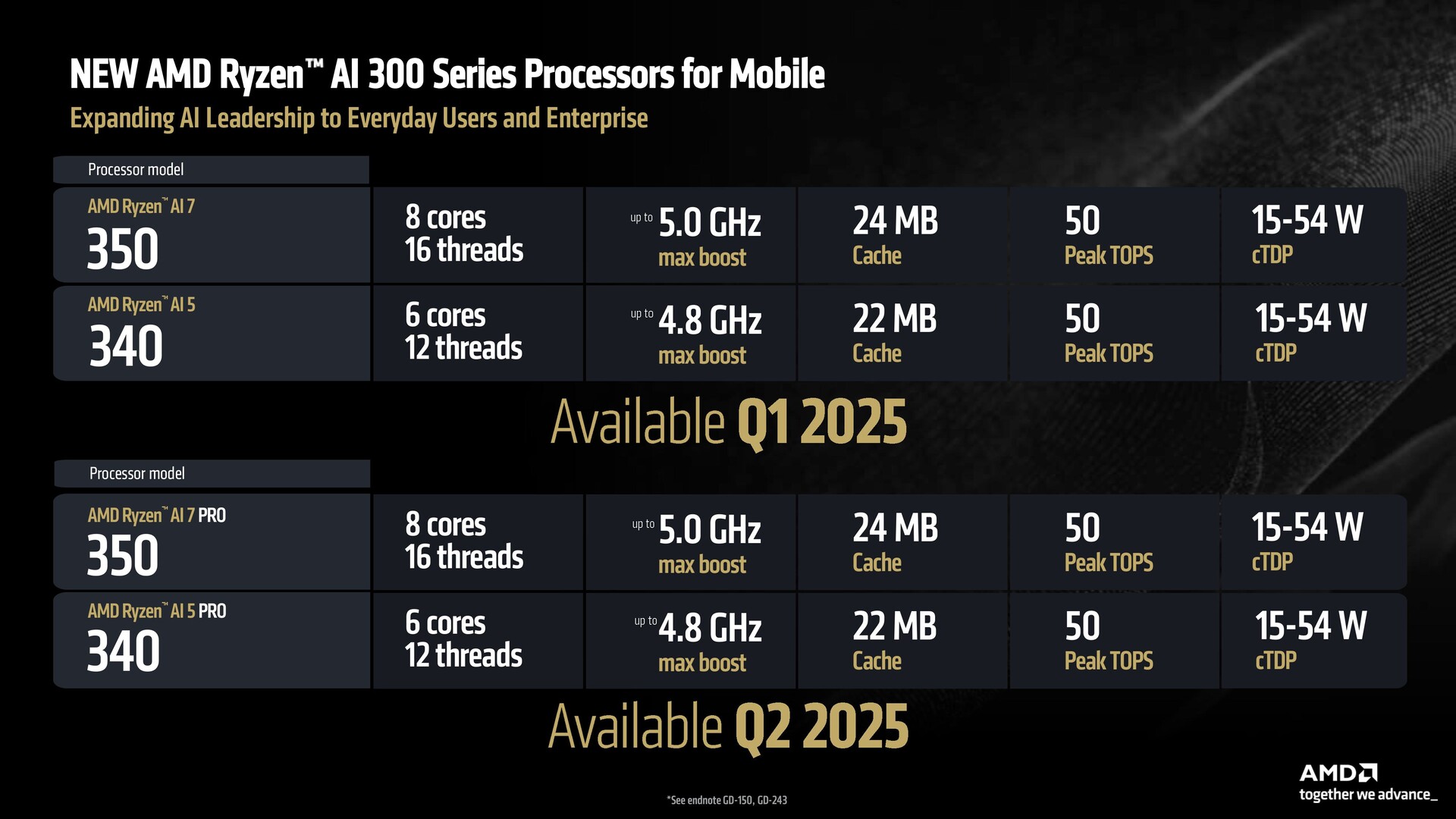
- La série Ryzen AI 300 offre un portefeuille complet pour les utilisateurs de toutes les exigences.
- Tous les modèles de la série Ryzen AI 300 et de la série Ryzen AI 200 sont compatibles avec les précédents lancements de Strix Point.
- Il n'est pas prévu d'intégrer les séries Ryzen AI 300 et 200 aux Chromebooks.
- L'implémentation "big Middle" d'AMD avec les cœurs Zen 5 et Zen 5c est un meilleur pari que l'approche P-core/E-core de la concurrence avec peu ou pas de pénalités d'ordonnancement.
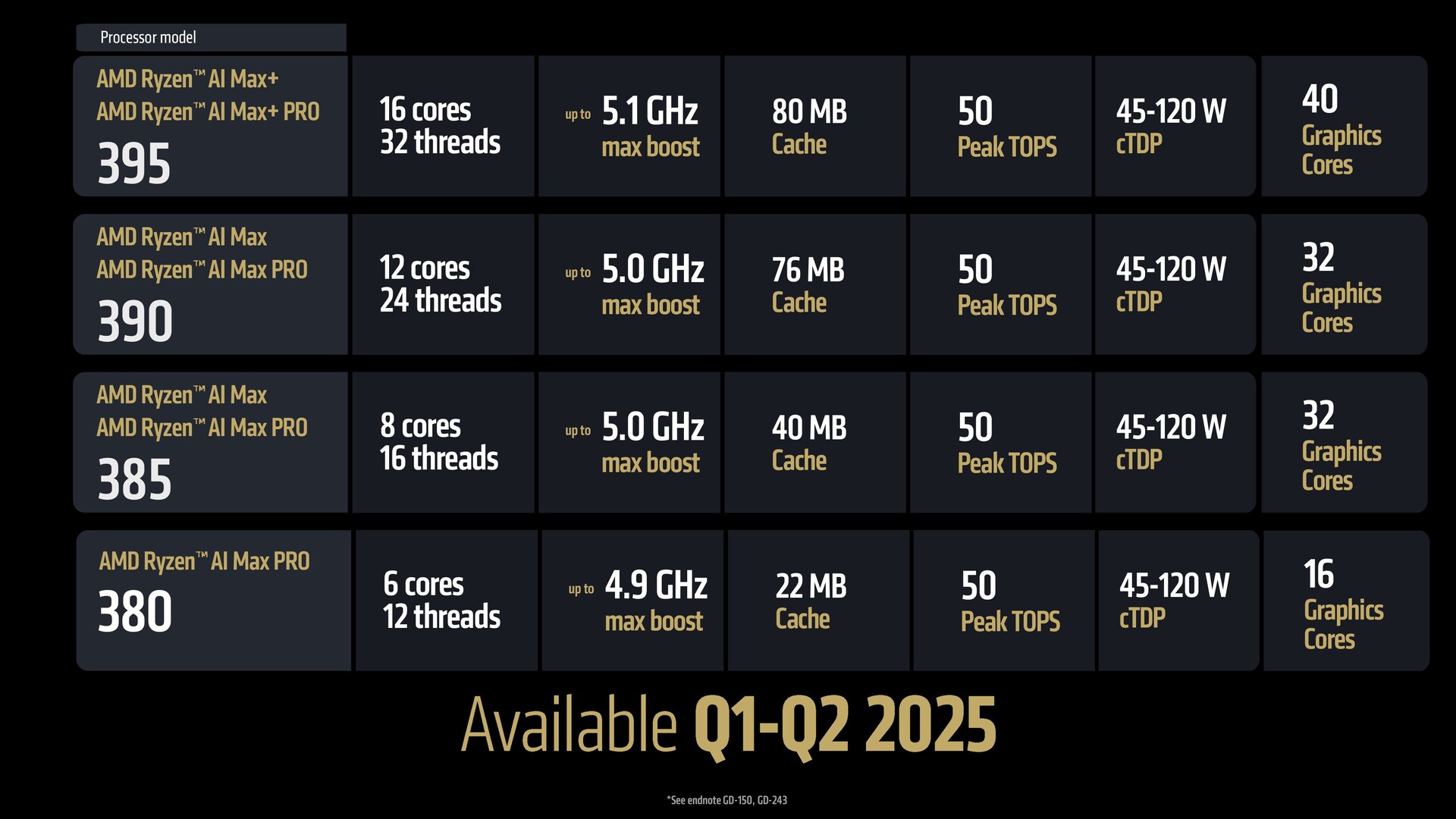
- Strix Halo Ryzen AI Max utilise les mêmes cœurs Zen 5 "classiques" que les pièces 3D Ryzen 9000 et Fire Range HX.
- Strix Halo est dérivé de l'ordinateur de bureau et dispose d'AVX-512, mais présente des interconnexions différentes optimisées pour la puissance.
- Le RDNA 3.5 du Strix Halo offre une bande passante mémoire équivalente à celle d'une RTX 4070 avec 32 Mo d'Infinity Cache. Il s'agit d'une décision consciente de ne pas opter pour la mémoire on-package.
- Les APU Ryzen AI utilisent un meilleur algorithme SmartShift optimisé pour les budgets énergétiques.
- Le Strix Halo ne prend pas en charge les dGPU et ne dispose que de 12 voies PCIe Gen 4 à partir du processeur. Il sera également disponible sur les mini-PC.
- Ryzen AI Max double la vitesse de la mémoire à LPDDR5-8000 et offre une bande passante similaire à celle de la RTX 4070.
- Aucun rafraîchissement de la gamme Dragon n'est prévu pour le moment, mais un futur rafraîchissement de la gamme Fire n'est pas exclu.
- RDNA 4 se concentrera uniquement sur les ordinateurs de bureau, mais les futurs dGPU et APU mobiles sont une possibilité certaine.
- Il est prévu d'apporter des capacités NPU à des prix plus bas au fil du temps.
L'avantage apparent de Ryzen AI
VS: Merci pour votre temps, Ben. Commençons par la façon dont AMD se voit avec les nouvelles annonces, son positionnement sur le marché et ses réflexions sur la concurrence, en particulier dans le segment des ordinateurs portables.
Ben: L'image globale est celle d'un grand potentiel. Nous avons le Ryzen AI 300, que nous étendons aux SKU Ryzen AI 7 et Ryzen AI 5. Nous avons également le Ryzen 9 9955HX3D pour les jeux haut de gamme et les stations de travail (ordinateurs portables). Enfin, nous avons le révolutionnaire Ryzen AI Max pour les jeux et les stations de travail minces et légères - une sorte de système qui réunit le meilleur de tous les éléments.
Par rapport à nos concurrents, la série Ryzen AI 300 est un couteau suisse. Elle est équipée d'un dGPU, ce qui lui permet de prendre en charge les jeux fins et légers. Si vous appréciez la possibilité de remplacer ou d'ajouter de la mémoire à votre système, il prend en charge l'extension DDR5, ce qui n'est pas le cas de la concurrence. Enfin, dans les systèmes de jeu, il offre également Copilot+.
Tous ces éléments le rendent unique. Nos concurrents doivent sortir plusieurs produits pour couvrir le même domaine, alors que nous sommes capables de faire tout cela avec la série 300. Et puis nous faisons des choses cool et folles comme le Ryzen AI Max, même en plus de cela.
Une autre contribution pour nos clients OEM dans les ordinateurs portables est que nous avons une histoire de compatibilité de paquet. Tous les modèles de la série 300, y compris le Strix Point que nous avons lancé cet été et le Kraken Point que nous lançons maintenant, sont compatibles et peuvent être proposés dans le même système. Tous les Ryzen de la série 200 basés sur le Hawk Point Zen 4 sont également compatibles.



Nous disposons donc d'un système à plusieurs niveaux de prix - Copilot+ et AI avec d'énormes capacités graphiques, jusqu'au N moins un produit qui est toujours excellent et qui continue à être très compétitif sur le marché.
Si l'acheteur apprécie les caractéristiques du châssis de cette plate-forme et qu'il la veut à un prix (inférieur), nous avons la série 200 et s'il veut l'évolutivité de l'IA et toutes les capacités de la série 300, nous l'avons aussi. Il y a de la flexibilité.
VS: Allez-vous proposer des produits de réduction pour les Chromebooks basés sur ces produits, comme ce que nous avons vu avec la série Ryzen 7020C ?
Ben: Nous n'avons pas de plans pour la série 300 dans les Chromebooks.
VS: Qu'en est-il de la série 200 ?
Ben: Je ne pense pas que nous ayons de projet pour la série 200 non plus (pour les Chromebooks).
L'approche "big middle" d'AMD avec Zen 5 et Zen 5c
VS: Les SKU haut de gamme sont-ils équipés d'un mélange de Zen 5 et de Zen 5c ou bien uniquement de Zen 5 ? Quelle serait la différence fondamentale entre ces cœurs ?
Ben: C'est une excellente question. De nombreux modèles de la série 300 proposent un mélange de Zen 5 " classique " et de Zen 5 " compact ". Nos concurrents utilisent l'approche "armée de petits cœurs" dans un grand nombre de leurs systèmes pour obtenir une référence en matière de multithreading.
Vous avez donc un grand nombre de petits cœurs minuscules qui peuvent ne pas être compatibles ISA, vous savez, il peut y avoir des traductions lorsque vous devez déplacer le processus entre les cœurs. C'est ce qu'ARM appelle big.LITTLE. Je qualifierais notre approche de "big Middle". Les cœurs compacts que nous avons utilisent le même jeu d'instructions et sont beaucoup plus performants que les cœurs super, super bas des autres.
Ainsi, dans une plate-forme où la puissance est limitée, vous disposez d'une fréquence maximale pour un thread. Vous ne pouvez pas faire fonctionner tous les cœurs de presque tous les ordinateurs portables à cette fréquence maximale en même temps. Ces cœurs compacts ont donc généralement une fréquence maximale un peu plus basse. Mais il n'y a pratiquement pas de pénalité, car si vous êtes dans un scénario à un seul thread, vous pouvez augmenter la fréquence de l'un des cœurs classiques.
Ces cœurs compacts se trouvent dans une zone sûre, ce qui nous permet de faire des choses intéressantes avec d'autres éléments de propriété intellectuelle. Ils offrent également une courbe de performance différente dans les cas où nous voulons que le processus soit sur un cœur à faible puissance, mais c'est essentiellement l'histoire ici.
Il ne s'agit pas d'une conversion énorme vers et entre les deux, et l'élément clé de ces (cœurs compacts) est qu'ils fonctionnent presque comme un cœur classique à des fréquences plus basses et ensuite, vous savez, ils ne s'adaptent pas aux fréquences plus élevées, ce qui n'a pas vraiment d'impact sur le système parce que vous avez l'adaptation à un seul thread dans les cœurs classiques.

Intel Thread Director face à l'idée d'AMD
VS: Vous dites donc que le système d'exploitation ne les considère pas comme des ISA différentes. Cela signifie qu'en théorie, au moins, une grande partie des problèmes potentiels d'ordonnancement devraient être résolus ?
Ben: Le système d'exploitation les considère comme des hétéro-cœurs, mais les pénalités pour ne pas être parfait dans l'ordonnancement sont beaucoup plus faibles.
VS: D'accord. En ce qui concerne l'aspect de l'ordonnancement ou la façon dont vous donnez la priorité au thread sur le cœur à utiliser, l'utilisateur peut-il disposer d'un frontend pour le contrôler ? Pour vous donner un peu de contexte, votre concurrent a quelque chose qui s'appelle le Thread Director. Ce qui se passe ici, c'est que la logique est décidée par le CPU. Mais nous avons souvent constaté que s'il parque un certain jeu ou un benchmark sur les cœurs E, les scores chutent, à moins que vous ne puissiez annuler manuellement cela avec des outils tiers.
AMD prévoit-il de donner le contrôle aux utilisateurs professionnels qui souhaitent jouer avec les threads, que ce soit dans le BIOS ou avec Ryzen Master ? Je pense qu'un contrôle basique des threads sera toujours présent dans le processeur. Mais s'il s'agit d'un programme comme Discord, et que je veux juste le pousser sur le cœur Zen 5c, est-ce possible ?
Ben: Notre concurrent a besoin de Thread Director en raison de l'énorme différence entre les cœurs. Par conséquent, si vous ne disposez pas de ce système, vous avez une très mauvaise expérience. Il existe d'ailleurs des jeux qui détectent le nombre de gros cœurs et ne génèrent des threads que pour ces cœurs en raison de la pénalité liée au contournement de tous les autres cœurs. Il existe plusieurs jeux qui génèrent différents nombres de threads en fonction du nombre de gros cœurs qu'ils évaluent dans le système.


Sur AMD, la pénalité est beaucoup plus faible. Je crois que vous avez quelques possibilités pour régler l'affinité des threads afin de faciliter les choses. Je ne suis pas vraiment au courant de toutes les fonctionnalités logicielles dont nous disposons pour effectuer la personnalisation. Nous devrions probablement revenir en arrière si nous pouvions essayer de trouver un responsable de produit logiciel interne qui pourrait vous donner la meilleure réponse.
Pour le contexte, Intel a critiqué l'absence d'un mécanisme similaire chez AMD tout en expliquant à ce qu'est Thread Director.
VS: Dans le portefeuille qui a été annoncé maintenant, avons-nous du Zen 5c dans l'une des UGS les plus haut de gamme ? Le Ryzen AI Max, je crois, est entièrement composé de Zen 5 ?
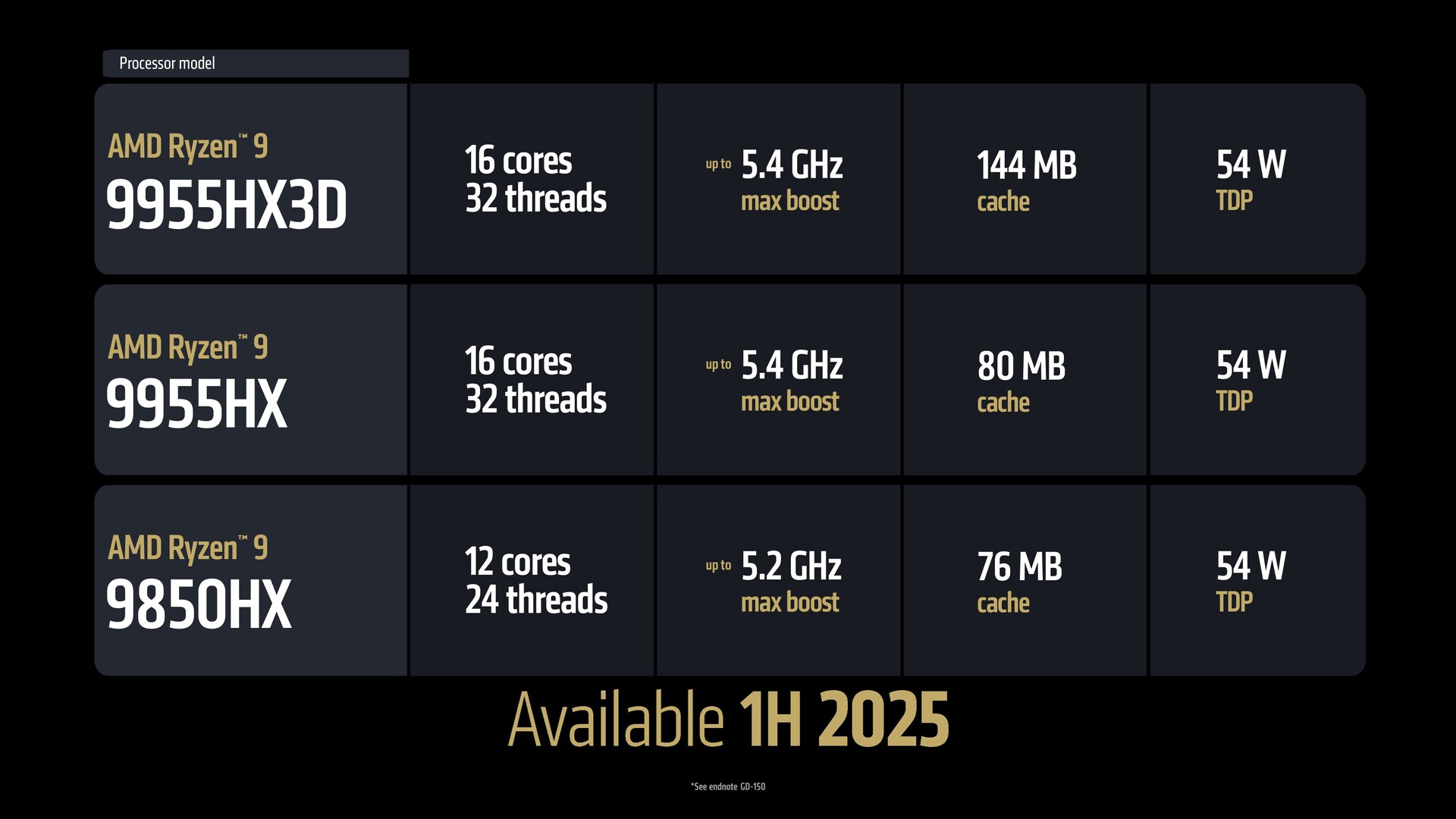
Ben: Oui, le Max est entièrement équipé de Zen 5. Il est également doté d'AVX-512, donc c'est une fonctionnalité de niveau serveur qui se trouve dans le Ryzen AI Max avec tous les cœurs classiques. C'est le maximum ; nous avons mis tout ce que nous avions là-dedans, donc la performance maximale, vous savez, les mêmes 16 cœurs classiques sont disponibles dans le 9950X3D et le Fire Range 9955HX3D. Cette même capacité est maintenant mise à l'échelle dans des facteurs de forme que ces plates-formes peuvent atteindre.
VS: La gamme Fire Range est-elle essentiellement une partie d'ordinateur de bureau intégrée dans une puce d'ordinateur portable ou y a-t-il d'autres améliorations spécifiques aux mobiles ? Je crois que le 9955HX3D est à 140 W tandis que le 9950X3D va jusqu'à 170 W ?
Ben: Oui, il s'agit du même silicium, et vous avez raison. C'est le binning, il y a le logiciel, il y a le tuning, il y a un package différent - ce sont les différences qui différencient ce produit, mais il utilise la même base qui alimente le 9950 sur l'ordinateur de bureau.
Décisions de conception derrière le Strix Halo Ryzen AI Max
VS: Les ordinateurs portables de la gamme Fire ne bénéficieront pas de la marque Copilot+, je crois, parce qu'il n'y a pas de NPU annoncé dessus ? En ce qui concerne les ordinateurs de bureau, si je me souviens bien, le Dr Lisa Su a déclaré lors de la présentation que nous avions l'AVX-512, qui devrait accélérer les charges de travail d'IA, mais il n'y a pas de NPU dédié en tant que tel sur l'ordinateur de bureau.
Ben: Ni les ordinateurs de bureau, ni les Fire Range n'ont de NPU dédié. Nous sommes absolument convaincus que le NPU fait partie de l'avenir. Je m'attends à ce que les tendances chez AMD et d'autres acteurs de l'industrie amènent des NPU dans ces capacités. Mais à ce jour, l'une des caractéristiques des ordinateurs de bureau et des Fire Range est qu'ils sont équipés à 100 % de dGPU. Vous avez donc une grande quantité d'IA dans le dGPU.
Nous concentrons d'abord notre NPU sur les plates-formes UMA. Ou vous savez, les plates-formes qui ont un mélange d'ordinateurs portables à faible consommation d'énergie. C'est la raison pour laquelle nous disposons d'une vaste gamme de NPU, la meilleure de tous les fournisseurs, je pense.
VS: Ce qui me fait penser qu'en parlant d'UMA, vous pensez que 256 Go/s devraient suffire pour la bande passante de la mémoire par rapport à, disons, Apple silicium ? Cette bande passante est-elle suffisante pour pousser les données d'un côté à l'autre des IP ? En outre, pourquoi n'y a-t-il pas de mémoire intégrée dans l'emballage ?
Ben: Le Ryzen AI Max utilise littéralement le double des puces LPDDR5 de la série Ryzen 300 ou de nos concurrents avec un bus de 128 bits. Il s'agit donc de puces de grande taille et l'emballage devient gigantesque. Ce que nous avons entendu de la part de nos clients, c'est qu'ils apprécient la flexibilité de pouvoir acheter de la mémoire et de prendre leurs propres décisions, et non pas que nous leur disions que vous avez deux options, que vous avez ceci ou cela. C'est pourquoi nous avons décidé de ne pas inclure la mémoire dans l'emballage.
En ce qui concerne la bande passante, puisque nous avons doublé la largeur du bus, à des vitesses LPDDR5-8000, elle est de 256 gigaoctets par seconde. Ce chiffre est identique à celui de la RTX 4070. À l'endroit où nous essayons de compléter, nous avons exactement la même bande passante, donc absolument oui. Si nous avions simplement ajouté beaucoup plus de graphiques sur l'APU sans doubler la bande passante de la mémoire, nous aurions été extrêmement limités.
Vous savez, nos architectes ne se contentent pas d'examiner une seule propriété intellectuelle et d'augmenter le chiffre. Vous devez considérer l'ensemble du système, vous assurer que vous disposez de la bande passante et de la puissance nécessaires. Nous disposons de 32 Mo de cache Infinity, une sorte de cache de niveau 4 sur la puce. C'est très similaire à l'Infinity Cache des cartes graphiques Radeon.
VS: Ce cache Infinity se trouve entre la Radeon 8060S et le CCD ?
Ben: Ce cache se trouve entre le reste de la puce et l'interface mémoire. Il s'agit donc d'un cache de dernier niveau similaire au mécanisme Infinity Cache de nos dGPU, qui se trouve entre le GPU et la mémoire GDDR6.
VS: Pensez-vous que le Strix Halo puisse être intégré dans d'autres facteurs de forme, comme un mini PC ?
Ben: Absolument. Nous avons quelques ordinateurs de bureau à petit facteur de forme ici (au CES). Je suis surpris par le nombre de personnes et d'OEM qui sont enthousiasmés par ce petit facteur de forme.

VS: Quel type d'interconnexion y a-t-il entre le CPU et le GPU RDNA 3.5 dans le Ryzen AI Max ? Avons-nous quelque chose du type Infinity fabric et SmartShift ?
Ben: L'interconnexion, nous l'appelons en interne DDR SSP. Je dois déterminer si cette marque interne est différente de celle utilisée dans la puce de bureau, parce que nous optimisons cette interconnexion pour la puissance. Lorsque vous tenez la puce Strix Halo, vous constatez que les CCD sont très proches de la puce d'E/S. C'est pourquoi nous avons été en mesure d'optimiser la puissance de l'interconnexion. C'est pourquoi nous avons pu économiser plusieurs watts d'énergie, ce qui est l'objectif de la conception de Strix Halo, à savoir une très faible consommation d'énergie pour des performances élevées. Il s'agit donc d'une interconnexion différente, et le silicium des CCD n'est pas identique à celui de nos puces de bureau.
Avec SmartShift, vous disposez d'un APU et d'un dGPU en tant que puces séparées, qui se partagent l'énergie. S'il détecte que le dGPU est en train d'atteindre son maximum, il lui alloue cette puissance. Les APU ont utilisé SmartShift - notre technologie SmartShift est basée sur un logiciel et se situe au niveau du micrologiciel entre ces deux puces.
Nos APU font effectivement du smart-shift, en partageant la puissance entre les IP au niveau matériel parce qu'ils forment un seul ensemble. Nos APU ont toujours eu, vous savez, quelque chose d'encore mieux, une pensée encore plus rapide, prenant cette décision plusieurs fois par seconde sur l'endroit où la puissance doit aller.
Donc, oui, effectivement, nous n'avons pas marqué cela (comme SmartShift) dans Ryzen AI Max, mais c'est juste inhérent au matériel d'un APU, cela s'est déjà produit.
VS: Et cela se répercute sur tous les APU de la pile ?
Ben: Absolument. Chaque APU alloue de la puissance en fonction des besoins. S'il y a une demande à la fois sur le dGPU et sur les cœurs, il regarde ce qui a le plus de demande et l'alloue.
VS: À ce propos, un OEM peut-il utiliser le Ryzen AI Max tout en proposant un dGPU, par exemple un dGPU Radeon ?
Ben: Le Ryzen AI Max ne supporte pas les dGPU. Puisque nous avons déjà un APU de classe dGPU, il n'y a vraiment aucune raison. Vous ne pouvez pas, vous savez, les CrossFire, donc il n'y a pas d'intérêt à les activer en même temps. Honnêtement, pourquoi un OEM achèterait-il cette solution et essaierait-il ensuite d'y ajouter un dGPU, puisque vous vous retrouvez maintenant dans une forme similaire à celle d'un facteur de forme de jeu existant.
VS: Dans ce cas, comment utiliseriez-vous au mieux les voies PCIe du CPU ? Je pense que beaucoup de voies seraient libres car la plupart des designs (minces) ont à peine un ou deux SSDs et les OEMs ont tendance à ne pas offrir d'extension de stockage dans ces châssis de toute façon, donc vous n'utilisez pas toute la bande passante PCIe.
Ben: Ces puces sont dotées de PCIe Gen 4. Ryzen AI Max offre 12 voies de PCIe Gen 4, et nos APU typiques qui ont un dGPU attaché ont 16 à 20 voies. La raison pour laquelle nous avons réduit ce nombre est que vous utilisez généralement huit voies pour le dGPU. Comme nous n'avons pas de dGPU attaché, vous savez, 20-8 revient à 12. Nous voulons être en mesure de prendre en charge les doubles SSD et quelques autres E/S, et je pense que certains de nos clients de stations de travail en profiteront.
VS: Donc, une possibilité serait que vous puissiez acheminer l'USB4 vers cela au lieu d'aller vers le chipset ?
Ben: Il faudrait que je vérifie cela. Habituellement, dans ce petit format, vous savez, il n'y a pas de puce de pont PCIe ou quoi que ce soit d'autre. Vous voulez simplement utiliser l'APU pour obtenir cette taille.
Nomenclature des produits et perspectives d'avenir
VS: De nouvelles puces Dragon Range Refresh sont-elles également prévues ?
Ben: Je pense que c'est peu probable. Je ne pense pas que nous annoncions quoi que ce soit dans la famille Dragon Range pour le moment.
VS: Cela signifie-t-il que vous continuerez à vendre les puces que vous avez vendues l'année dernière ?
Ben: Certainement. Même si un APU n'est pas dans notre feuille de route actuelle, si les OEM construisent encore des systèmes avec les designs précédents, absolument. Il existe une longue tradition de vente de produits existants sur plusieurs années. Ce n'est pas comme si vous conceviez un nouveau système avec ceci, mais hé, le système se vend très bien, donc il se porte bien, et cela continuera.
VS: Cela impliquerait, bien que ce ne soit pas officiel, que vous n'excluez pas totalement la possibilité de voir des puces rafraîchies avec un nouveau schéma de dénomination ou quelque chose comme ça ?
Ben: Vous savez, dans nos schémas de dénomination, nous voulons faciliter la décision des clients. Parfois, nous considérons un rafraîchissement comme la série 200. Il s'agit en grande partie d'une ligne de produits rafraîchie. Elle n'est pas entièrement nouvelle. Mais la raison en est qu'il est vraiment bizarre pour un client d'avoir une série 300, une série 8000, et de se demander... attendez, 8000 c'est moins que 300, ça n'a pas de sens ! C'est donc en partie pour cette raison.
Dans la génération actuelle, nous voulons que la marque soit cohérente et facile à comprendre. Aujourd'hui, il s'agit essentiellement d'une marque à trois chiffres, plus le nombre est élevé, mieux c'est. Ainsi, 200 c'est Hawk, et puis, vous savez, en 300 vous avez Strix Point et Kraken, et le Max tout en haut. C'est une stratégie de marque cohérente. Je pense que nous ferons quelque chose dans ce domaine pour le lancement de Fire Range également.
VS: Je veux dire, il est vrai qu'il n'est pas toujours facile de prononcer le nom complet de la puce d'un seul coup "Ryzen.AI.9.300.Max.Plus" !
Ben: Je pense que plusieurs d'entre nous, vous savez, eh bien, laissez-moi juste dire que dans le domaine d'AMD, nous avons tellement de produits, que c'est difficile. Nous voulons que les produits soient cohérents, nous voulons qu'ils soient différenciés, nous voulons que les consommateurs le sachent. Honnêtement, lorsqu'un consommateur se rend dans un magasin, je pense qu'il voit Copilot+ et qu'il voit 9, 7, 5, 3. C'est probablement... c'est suffisant. Il ne regarde pas le numéro de modèle exact.
Nous sommes tous (en référence aux enthousiastes) un peu comme des joueurs de baseball, n'est-ce pas ? Vous voulez connaître tous les détails, alors je pense que c'est une partie des différences.
VS: Et voyez-vous des perspectives pour les ordinateurs portables RDNA 4 à l'avenir ? Malheureusement, le nombre d'ordinateurs portables équipés d'un dGPU AMD a été plutôt anémique.
Ben: Notre stratégie graphique actuelle est axée sur le marché des ordinateurs de bureau avec RDNA 4. Je pense donc que vous verrez d'abord ce type de produits à l'avenir. Il est certain que RDNA 4 et les futures technologies graphiques seront intégrées dans les ordinateurs portables, qu'il s'agisse d'APU ou de futurs produits.
VS: C'est probablement futuriste, mais nous avons entendu dire que RDNA et CDNA seraient combinés.
Ben: Oui, c'est un projet à long terme d'unifier les deux, et je suis personnellement très enthousiaste à ce sujet parce que le ML est en fait l'orientation que prendra le marché des clients à long terme. Je pense donc qu'il serait très positif que tout le monde aille dans la même direction.
VS: D'accord, une dernière question, et c'est aussi l'une de mes bêtes noires. Je pense qu'il y a beaucoup de place pour le bas de gamme, parce que tout le monde ne veut pas d'une puce très haut de gamme pour ses besoins. Des choses comme l'édition 1080p de base, la plupart des puces peuvent le faire aujourd'hui. Pourquoi AMD ne se concentre-t-il pas sur, disons, un Ryzen 3 parce que, vous savez, vous offrez un NPU 50 TOPS sur l'ensemble de la pile. Pourquoi ne pas faire la même chose du côté du GPU ? Ou peut-être tirer parti du NPU lui-même et nous donner un produit d'entrée de gamme sur lequel vous pouvez faire de la création de contenu de base et d'autres choses.
On peut même descendre encore plus bas. Comme vous le savez, il y a eu un produit appelé Ryzen Embedded R1606Gque nous avons vu dans un ou deux mini PC.
Ben: Nous avons donc l'intention d'amener le NPU à de meilleurs prix sur le marché au fil du temps. Je pense que l'industrie s'oriente également dans cette direction. Nous voulons donc absolument offrir à chaque consommateur un PC Copilot+, une expérience AI basée sur le NPU. Il suffit d'examiner les aspects économiques et les prix de ces produits, et il s'agit simplement d'une question de silicium, d'accord, que pouvons-nous y ajouter ?
Par exemple, nous pourrions faire passer l'interface mémoire à 64 bits. Mais qu'est-ce que cela implique pour le reste du système ? Combien de cœurs faut-il au minimum pour obtenir ce type de performances ? Je dirais qu'au cours des deux dernières années, le NPU n'est plus un accessoire. C'est l'une des trois trinités des IP sur lesquelles nous devons nous concentrer. Nous essayons donc absolument de dimensionner ces trois éléments dans tous les segments.
Source(s)
Propre à l'entreprise





