

Meta dévoile le Llama 3.1 405B AI, le plus grand, le plus intelligent et le plus libre de droits

Meta a dévoilé son Llama 3.1 405B AI pour une utilisation libre de droits. Le grand modèle de langage (LLM) de 750 Go et 405 milliards de paramètres est l'un des plus grands jamais publiés, ce qui lui permet d'être compétitif avec sa fenêtre d'entrée élargie de 128K tokens face à des fleurons de l'IA tels que Anthropic Claude 3.5 Sonnet et OpenAI GPT-4o. Contrairement aux concurrents payants à code source fermé, les lecteurs peuvent personnaliser et exécuter le LLM gratuit sur leurs propres ordinateurs équipés de cartes graphiques (GPU) Nvidia extrêmement puissantes.
Création et énergie
Meta a exploité jusqu'à 16 384 GPU 700W TDP H100 sur sa plateforme de serveur d'IA Meta Grand Teton pour produire les 3,8 x 10^25 FLOPs nécessaires à la création d'un modèle de 405 milliards de paramètres sur 16,55 billions de jetons (1 000 jetons représentent environ 750 mots). Les pannes liées au GPU ont représenté 57,3 % du temps d'arrêt pendant la préformation, dont 30,1 % dus à des GPU défectueux.
Plus de 54 jours ont été consacrés au pré-entraînement de l'IA sur des documents, avec un total de 39,3 millions d'heures GPU utilisées pour entraîner Llama 3.1 405B. Selon une estimation rapide, la consommation d'électricité pendant la formation s'élève à plus de 11 GWh, et 11 390 tonnes d'équivalent CO2 de gaz à effet de serre ont été émises.
Sécurité et performance
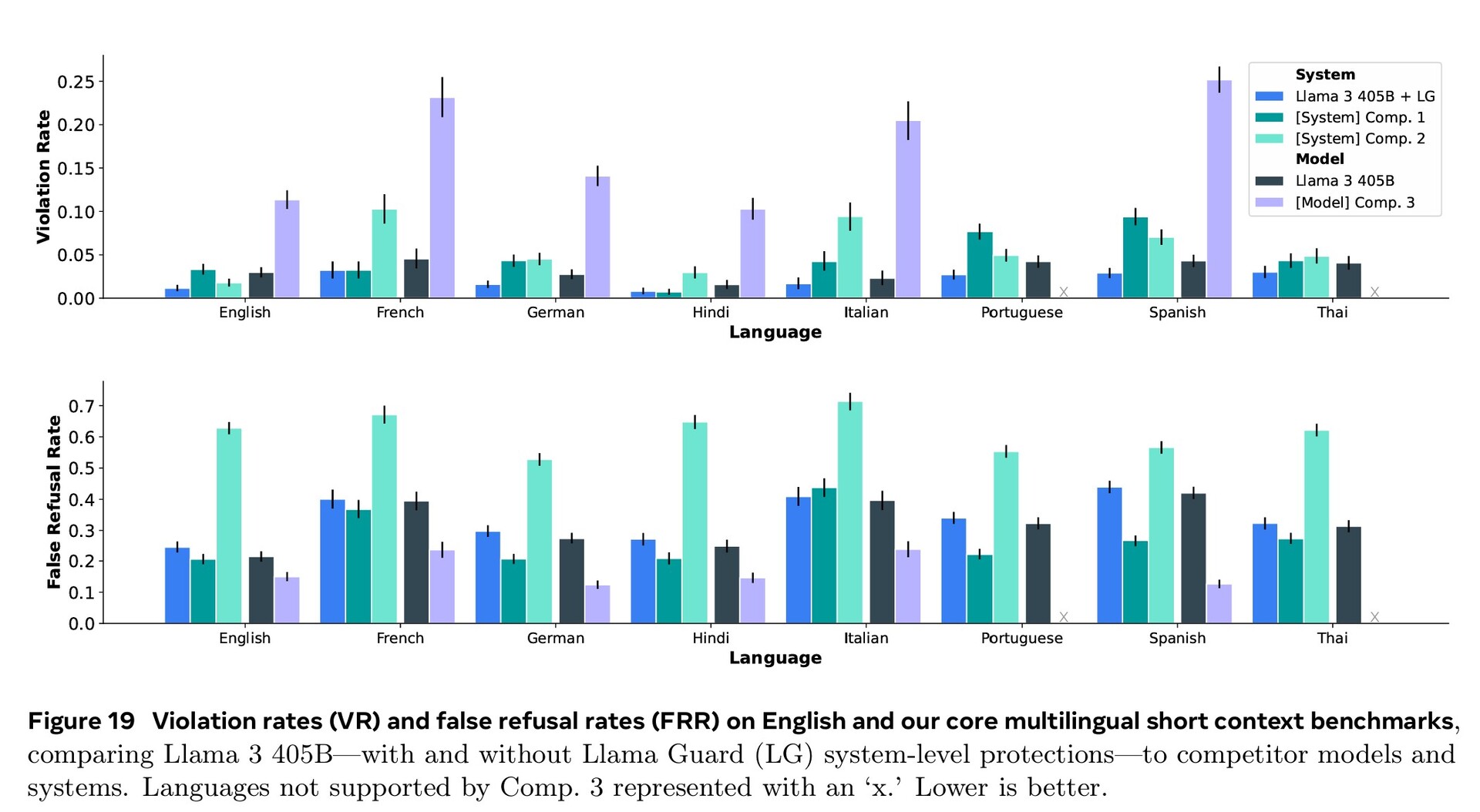
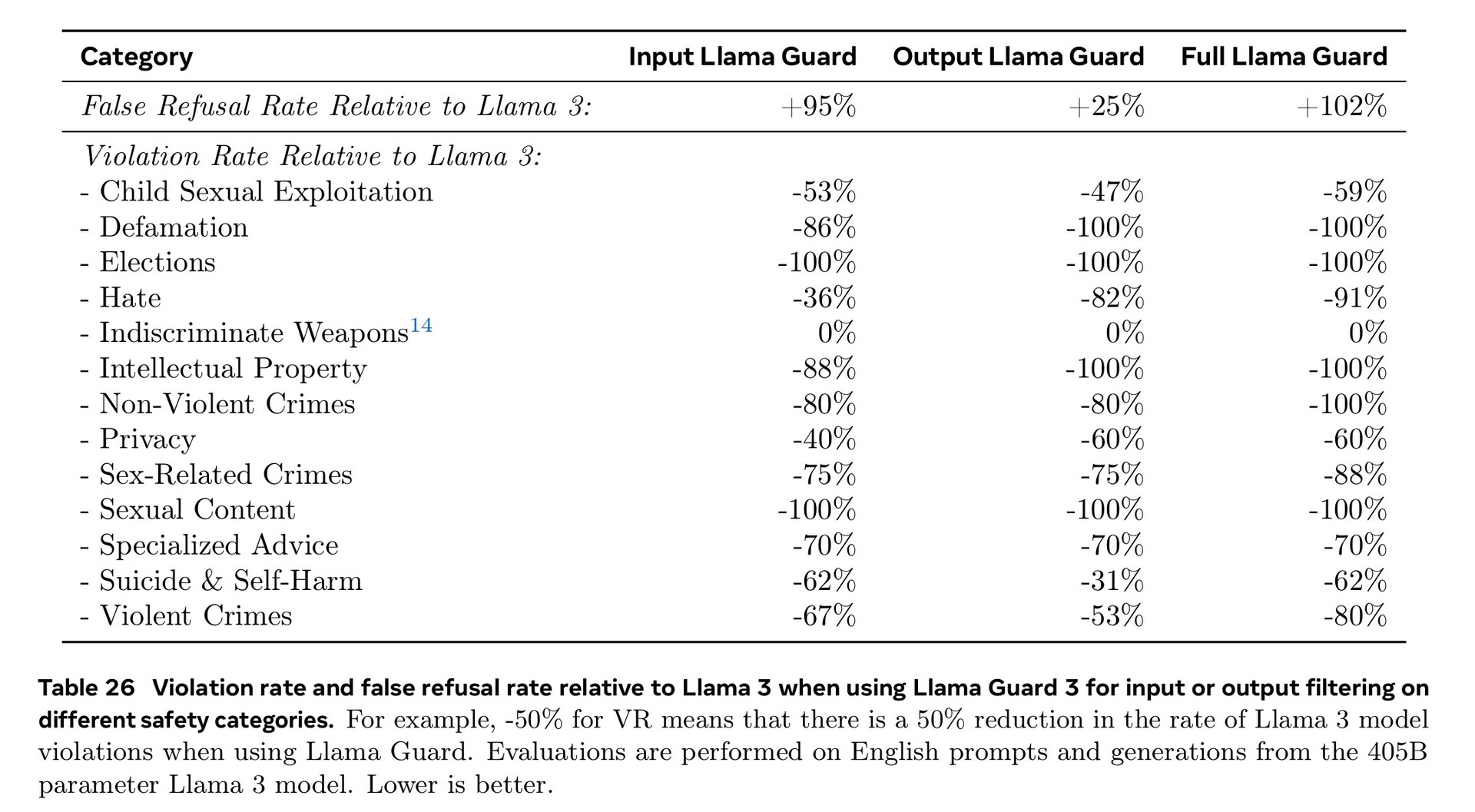
L'entraînement intensif dans les domaines de la cybersécurité, de la sécurité des enfants, des attaques chimiques et biologiques, de l'injection rapide, etc., ainsi que le filtrage des textes d'entrée et de sortie à l'aide de Llama Guard 3 ont permis d'obtenir de meilleures performances en matière de sécurité que les modèles d'IA concurrents. Cependant, le nombre réduit de documents en langues étrangères disponibles pour la formation signifie que le Llama 3.1 est plus susceptible de répondre à des questions dangereuses en portugais ou en français qu'en anglais.
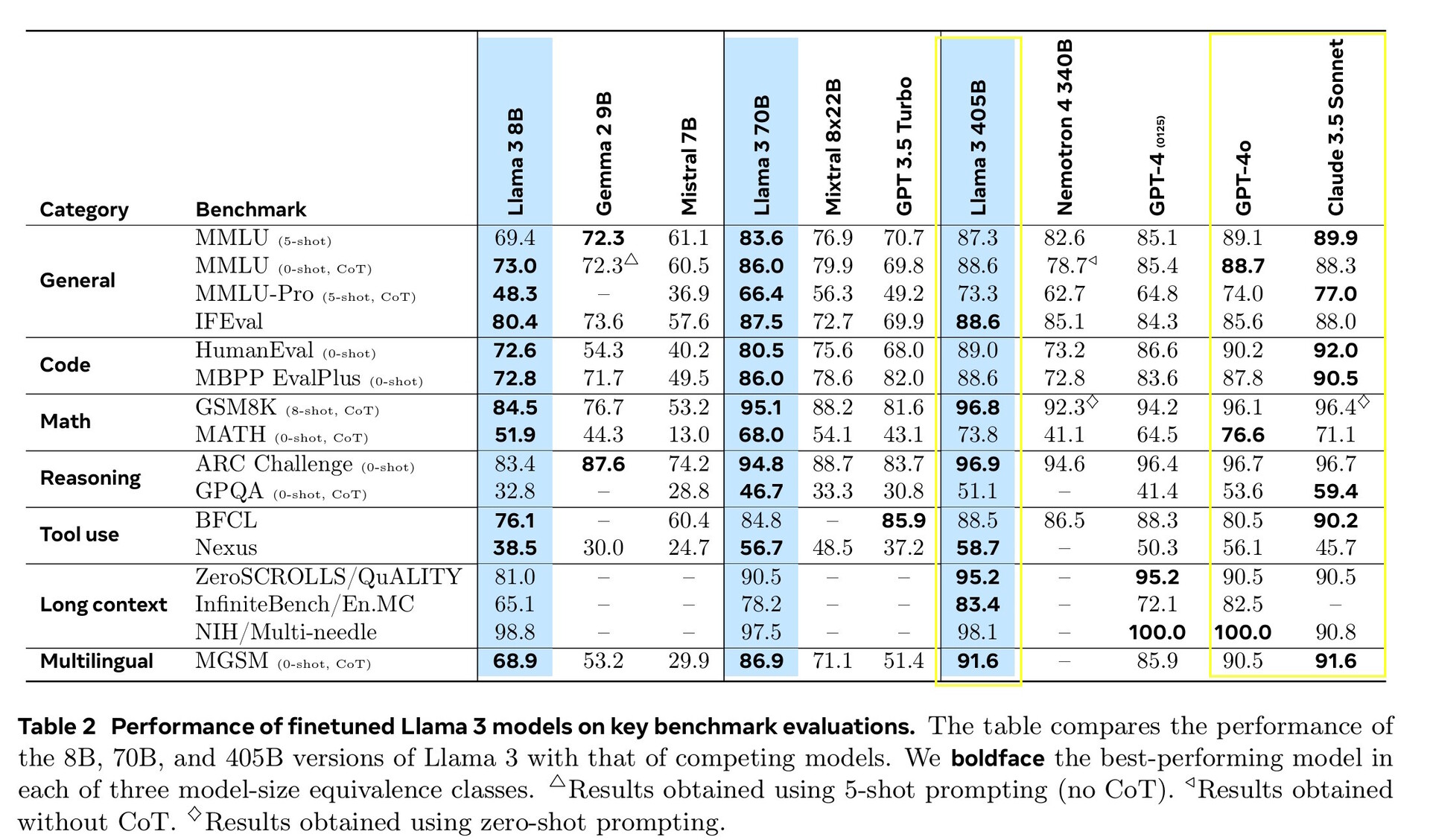
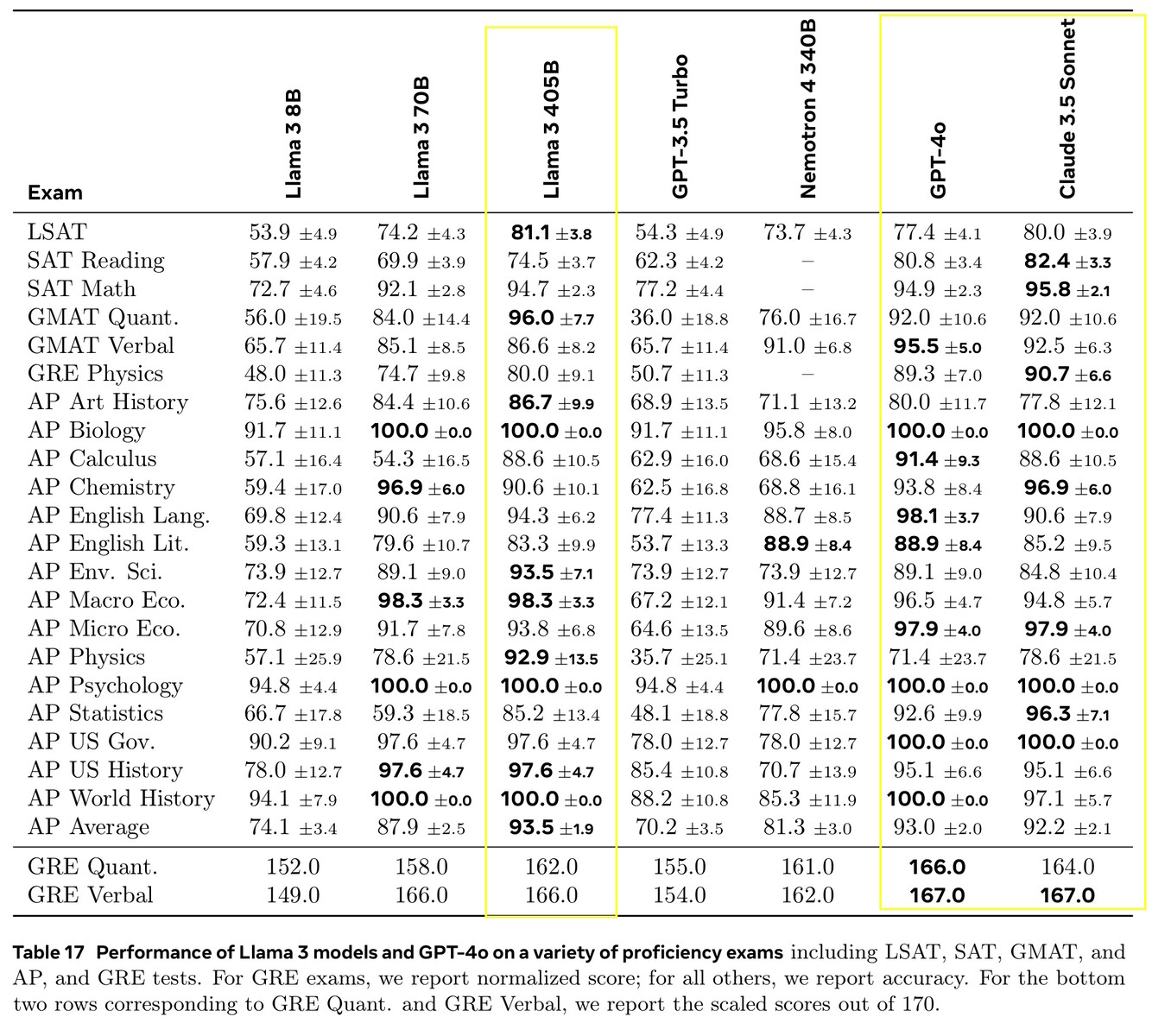
Llama 3.1 405B a obtenu des scores compris entre 51,1 et 96,6 % lors de tests d'IA de niveau universitaire et supérieur, ce qui correspond à Claude 3.5 Sonnet et GPT-4o. Dans les tests de la vie réelle notés par des humains, GPT-4o a fourni de meilleures réponses 52,9 % plus souvent que Llama. Le modèle ne sait rien au-delà de la date limite de connaissance de décembre 2023, mais il peut recueillir les dernières informations en ligne à l'aide de Brave Searchrésoudre des problèmes mathématiques à l'aide de Wolfram Alphaet résoudre des problèmes de codage à l'aide de l'interpréteur Python https://www.python.org/.
Exigences
Les chercheurs souhaitant exécuter Llama 3.1 405B localement devront disposer d'ordinateurs extrêmement puissants et de 750 Go d'espace de stockage libre. L'exécution du modèle complet nécessite huit Nvidia A100 GPU nvidia A100 ou similaires, fournissant deux nœuds de MP16 et 810 Go de VRAM GPU pour l'inférence, dans un système avec 1 To de RAM. Meta a publié des versions plus petites qui nécessitent moins de ressources mais qui sont moins performantes : Llama 3.1 8B et 70B. Llama 3.1 8B n'a besoin que de 16 Go de VRAM pour le GPU, il fonctionnera donc parfaitement sur un système bien équipé de Nvidia 4090(comme cet ordinateur portable sur Amazon) au niveau de GPT-3.5 Turbo. Les lecteurs qui souhaitent simplement utiliser une IA de haut niveau peuvent installer une application telle que Anthropic Android ou application iOS.
Source(s)
Grand modèle linguistique
Voici Llama 3.1 : Nos modèles les plus performants à ce jour
23 juillet 2024
15 minutes de lecture
A retenir :
Meta s'engage à rendre l'IA accessible à tous. Lisez la lettre de Mark Zuckerberg expliquant pourquoi l'open source est bon pour les développeurs, bon pour Meta et bon pour le monde.
En mettant l'intelligence ouverte à la portée de tous, nos derniers modèles étendent la longueur du contexte à 128K, ajoutent le support de huit langues et incluent le Llama 3.1 405B, le premier modèle d'IA open source de niveau frontière.
Le Llama 3.1 405B est une classe à part, avec une flexibilité inégalée, un contrôle et des capacités de pointe qui rivalisent avec les meilleurs modèles à code source fermé. Notre nouveau modèle permettra à la communauté de débloquer de nouveaux flux de travail, tels que la génération de données synthétiques et la distillation de modèles.
Nous continuons à développer Llama pour en faire un système en fournissant davantage de composants qui fonctionnent avec le modèle, y compris un système de référence. Nous voulons donner aux développeurs les outils nécessaires pour créer leurs propres agents personnalisés et de nouveaux types de comportements agentiques. Nous renforçons cela avec de nouveaux outils de sécurité et de sûreté, y compris Llama Guard 3 et Prompt Guard, pour aider à construire de manière responsable. Nous lançons également un appel à commentaires sur l'API Llama Stack, une interface standard qui, nous l'espérons, permettra aux projets tiers d'exploiter plus facilement les modèles Llama.
L'écosystème est prêt à démarrer avec plus de 25 partenaires, dont AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud et Snowflake, qui proposent des services dès le premier jour.
Essayez Llama 3.1 405B aux États-Unis sur WhatsApp et sur meta.ai en posant une question difficile de mathématiques ou de codage.
LECTURES RECOMMANDÉES
Développer l'écosystème des lamas de manière responsable
L'écosystème du lama : Passé, présent et futur
Jusqu'à aujourd'hui, les modèles linguistiques à grande échelle en open source étaient souvent à la traîne de leurs homologues fermés en termes de capacités et de performances. Aujourd'hui, nous entrons dans une nouvelle ère où l'open source montre la voie. Nous publions Meta Llama 3.1 405B, que nous considérons comme le modèle de base le plus grand et le plus performant au monde. Avec plus de 300 millions de téléchargements de toutes les versions de Llama à ce jour, nous ne faisons que commencer.
Présentation de Llama 3.1
Llama 3.1 405B est le premier modèle en libre accès qui rivalise avec les meilleurs modèles d'intelligence artificielle en ce qui concerne les capacités de pointe en matière de connaissances générales, d'orientation, de mathématiques, d'utilisation d'outils et de traduction multilingue. Avec la sortie du modèle 405B, nous sommes prêts à stimuler l'innovation, avec des possibilités de croissance et d'exploration sans précédent. Nous pensons que la dernière génération de Llama va donner naissance à de nouvelles applications et à de nouveaux paradigmes de modélisation, y compris la génération de données synthétiques pour permettre l'amélioration et l'entraînement de modèles plus petits, ainsi que la distillation de modèles - une capacité qui n'a jamais été atteinte à cette échelle dans le domaine de l'open source.
Dans le cadre de cette dernière version, nous introduisons des versions améliorées des modèles 8B et 70B. Ceux-ci sont multilingues et disposent d'une longueur de contexte nettement supérieure (128 Ko), d'outils de pointe et de capacités de raisonnement globalement plus puissantes. Cela permet à nos derniers modèles de prendre en charge des cas d'utilisation avancés, tels que le résumé de textes longs, les agents conversationnels multilingues et les assistants de codage. Nous avons également modifié notre licence, ce qui permet aux développeurs d'utiliser les résultats des modèles Llama, y compris le 405B, pour améliorer d'autres modèles. Fidèles à notre engagement en faveur de l'open source, nous mettons dès aujourd'hui ces modèles à la disposition de la communauté pour téléchargement sur llama.meta.com et Hugging Face, ainsi que pour développement immédiat sur notre vaste écosystème de plates-formes partenaires.
Évaluation des modèles
Pour cette version, nous avons évalué les performances sur plus de 150 ensembles de données de référence couvrant un large éventail de langues. En outre, nous avons réalisé des évaluations humaines approfondies qui comparent Llama 3.1 à des modèles concurrents dans des scénarios réels. Notre évaluation expérimentale suggère que notre modèle phare est compétitif par rapport aux principaux modèles de base sur une gamme de tâches, y compris GPT-4, GPT-4o, et Claude 3.5 Sonnet. En outre, nos petits modèles sont compétitifs par rapport aux modèles fermés et ouverts qui ont un nombre similaire de paramètres.
Architecture du modèle
L'entraînement de Llama 3.1 405B sur plus de 15 trillions de tokens a été un défi majeur pour notre plus grand modèle à ce jour. Pour permettre des entraînements à cette échelle et obtenir les résultats que nous avons obtenus dans un délai raisonnable, nous avons considérablement optimisé notre pile d'entraînement complète et poussé l'entraînement de notre modèle sur plus de 16 000 GPU H100, faisant du 405B le premier modèle Llama entraîné à cette échelle.
Pour y remédier, nous avons fait des choix de conception qui visent à rendre le processus de développement du modèle évolutif et simple.
Nous avons opté pour une architecture de modèle de transformateur de décodeur seul standard avec des adaptations mineures plutôt que pour un modèle de mélange d'experts afin de maximiser la stabilité de l'entraînement.
Nous avons adopté une procédure itérative de post-entraînement, où chaque tour utilise un réglage fin supervisé et une optimisation directe des préférences. Cela nous a permis de créer des données synthétiques de la plus haute qualité pour chaque cycle et d'améliorer les performances de chaque capacité.
Par rapport aux versions précédentes de Llama, nous avons amélioré à la fois la quantité et la qualité des données que nous utilisons pour la pré- et la post-formation. Ces améliorations comprennent le développement de pipelines de prétraitement et de curation plus minutieux pour les données de pré-entraînement, le développement d'une assurance qualité plus rigoureuse et des approches de filtrage pour les données de post-entraînement.
Comme prévu par les lois d'échelle pour les modèles de langage, notre nouveau modèle phare surpasse les modèles plus petits formés à l'aide de la même procédure. Nous avons également utilisé le modèle de paramètres 405B pour améliorer la qualité post-entraînement de nos modèles plus petits.
Pour soutenir l'inférence de production à grande échelle pour un modèle à l'échelle du 405B, nous avons quantifié nos modèles de 16 bits (BF16) à 8 bits (FP8) numériques, réduisant efficacement les exigences de calcul nécessaires et permettant au modèle de fonctionner dans un seul nœud de serveur.
Mise au point de l'instruction et du chat
Avec le Llama 3.1 405B, nous nous sommes efforcés d'améliorer l'utilité, la qualité et la capacité du modèle à suivre des instructions détaillées en réponse aux instructions de l'utilisateur, tout en garantissant des niveaux élevés de sécurité. Nos plus grands défis ont été la prise en charge d'un plus grand nombre de capacités, la fenêtre contextuelle de 128K et l'augmentation de la taille des modèles.
En post-entraînement, nous produisons des modèles de chat finaux en effectuant plusieurs cycles d'alignement sur le modèle pré-entraîné. Chaque cycle implique un réglage fin supervisé (SFT), un échantillonnage de rejet (RS) et une optimisation directe des préférences (DPO). Nous utilisons la génération de données synthétiques pour produire la grande majorité de nos exemples de SFT, en itérant plusieurs fois pour produire des données synthétiques de qualité de plus en plus élevée pour toutes les capacités. En outre, nous investissons dans de multiples techniques de traitement des données pour filtrer ces données synthétiques afin d'obtenir la meilleure qualité possible. Cela nous permet d'adapter la quantité de données de mise au point à l'ensemble des capacités.
Nous équilibrons soigneusement les données afin de produire un modèle de haute qualité pour toutes les capacités. Par exemple, nous maintenons la qualité de notre modèle sur les benchmarks à contexte court, même lorsque nous l'étendons à un contexte de 128K. De même, notre modèle continue de fournir des réponses maximales, même lorsque nous ajoutons des mesures de sécurité.
Le système Llama
Les modèles Llama ont toujours été conçus pour fonctionner dans le cadre d'un système global capable d'orchestrer plusieurs composants, y compris l'appel à des outils externes. Notre vision est d'aller au-delà des modèles de base pour donner aux développeurs l'accès à un système plus large qui leur donne la flexibilité de concevoir et de créer des offres personnalisées qui s'alignent sur leur vision. Cette réflexion a débuté l'année dernière lorsque nous avons introduit pour la première fois l'incorporation de composants en dehors du LLM de base.
Dans le cadre de nos efforts continus pour développer l'IA de manière responsable au-delà de la couche de modèle et aider les autres à faire de même, nous publions un système de référence complet qui comprend plusieurs exemples d'applications et de nouveaux composants tels que Llama Guard 3, un modèle de sécurité multilingue, et Prompt Guard, un filtre d'injection d'invite. Ces exemples d'applications sont libres et peuvent être développés par la communauté.
La mise en œuvre des composants de cette vision du système Llama est encore fragmentée. C'est pourquoi nous avons commencé à travailler avec l'industrie, les startups et la communauté au sens large pour aider à mieux définir les interfaces de ces composants. Pour ce faire, nous lançons un appel à commentaires sur GitHub pour ce que nous appelons "Llama Stack" Llama Stack est un ensemble d'interfaces standardisées et validées pour la construction de composants canoniques de la chaîne d'outils (réglage fin, génération de données synthétiques) et d'applications agentiques. Nous espérons que ces interfaces seront adoptées par l'ensemble de l'écosystème, ce qui devrait faciliter l'interopérabilité.
Nous vous invitons à nous faire part de vos commentaires et des moyens d'améliorer la proposition. Nous sommes impatients de développer l'écosystème autour de Llama et d'abaisser les barrières pour les développeurs et les fournisseurs de plateformes.
L'ouverture stimule l'innovation
Contrairement aux modèles fermés, les poids des modèles Llama peuvent être téléchargés. Les développeurs peuvent entièrement adapter les modèles à leurs besoins et à leurs applications, s'entraîner sur de nouveaux ensembles de données et procéder à des ajustements supplémentaires. Cela permet à l'ensemble de la communauté des développeurs et au monde entier de profiter pleinement de la puissance de l'IA générative. Les développeurs peuvent entièrement personnaliser leurs applications et les exécuter dans n'importe quel environnement, que ce soit sur site, dans le nuage ou même localement sur un ordinateur portable, le tout sans partager de données avec Meta.
Bien que beaucoup puissent affirmer que les modèles fermés sont plus rentables, les modèles Llama offrent un coût par jeton parmi les plus bas de l'industrie, selon les tests effectués par Artificial Analysis. Comme l'a souligné Mark Zuckerberg, l'open source permettra à un plus grand nombre de personnes dans le monde d'accéder aux avantages et aux possibilités de l'IA, de ne pas concentrer le pouvoir entre les mains d'un petit nombre et de déployer la technologie de manière plus homogène et plus sûre dans l'ensemble de la société. C'est pourquoi nous continuons à prendre des mesures pour que l'IA en libre accès devienne la norme du secteur.
Nous avons vu la communauté réaliser des choses étonnantes avec les modèles Llama précédents, notamment un compagnon d'étude IA construit avec Llama et déployé dans WhatsApp et Messenger, un LLM adapté au domaine médical conçu pour aider à guider la prise de décision clinique, et une startup à but non lucratif dans le domaine de la santé au Brésil qui permet au système de santé d'organiser et de communiquer plus facilement les informations relatives à l'hospitalisation des patients, tout cela en sécurisant les données. Nous sommes impatients de voir ce qu'ils construiront avec nos derniers modèles grâce à la puissance de l'open source.
Construire avec Llama 3.1 405B
Pour le développeur moyen, l'utilisation d'un modèle à l'échelle du 405B est un défi. Bien qu'il s'agisse d'un modèle incroyablement puissant, nous reconnaissons qu'il nécessite des ressources de calcul et une expertise considérables. Nous avons discuté avec la communauté et nous nous rendons compte que le développement de l'IA générative ne se limite pas aux modèles d'incitation. Nous voulons permettre à chacun de tirer le meilleur parti de la 405B, y compris :
Inférence en temps réel et par lots
Mise au point supervisée
Évaluation de votre modèle pour votre application spécifique
Pré-entraînement continu
Génération améliorée par récupération (RAG)
Appel de fonction
Génération de données synthétiques
C'est là que l'écosystème Llama peut vous aider. Dès le premier jour, les développeurs peuvent profiter de toutes les capacités avancées du modèle 405B et commencer à construire immédiatement. Les développeurs peuvent également explorer des flux de travail avancés tels que la génération de données synthétiques facile à utiliser, suivre des instructions clés en main pour la distillation de modèles et permettre une RAG transparente avec des solutions de partenaires, notamment AWS, NVIDIA et Databricks. En outre, Groq a optimisé l'inférence à faible latence pour les déploiements dans le nuage, Dell réalisant des optimisations similaires pour les systèmes sur site.
Nous avons travaillé avec des projets communautaires clés tels que vLLM, TensorRT et PyTorch afin d'intégrer le support dès le premier jour et de s'assurer que la communauté est prête pour le déploiement en production.
Nous espérons que notre version du 405B stimulera également l'innovation au sein de la communauté élargie afin de faciliter l'inférence et le réglage fin des modèles de cette échelle et de permettre la prochaine vague de recherche sur la distillation de modèles.
Essayez la collection de modèles Llama 3.1 dès aujourd'hui
Nous sommes impatients de voir ce que la communauté fera de ce travail. Il y a tellement de potentiel pour construire de nouvelles expériences utiles en utilisant le multilinguisme et l'augmentation de la longueur du contexte. Avec la pile Llama et les nouveaux outils de sécurité, nous sommes impatients de continuer à construire avec la communauté open source de manière responsable. Avant de publier un modèle, nous nous efforçons d'identifier, d'évaluer et d'atténuer les risques potentiels par le biais de plusieurs mesures, notamment des exercices de découverte des risques avant le déploiement, par le biais de l'équipe rouge, et des ajustements de sécurité. Par exemple, nous menons des exercices intensifs avec des experts externes et internes pour tester les modèles et trouver des façons inattendues de les utiliser. (Pour en savoir plus sur la façon dont nous développons notre collection de modèles Llama 3.1 de manière responsable, lisez cet article de blog)
Bien qu'il s'agisse de notre plus grand modèle à ce jour, nous pensons qu'il y a encore beaucoup de nouvelles pistes à explorer à l'avenir, notamment des tailles plus adaptées aux appareils, des modalités supplémentaires et davantage d'investissements dans la couche de la plateforme d'agents.
Ce travail a été soutenu par nos partenaires de la communauté de l'IA. Nous tenons à les remercier (par ordre alphabétique) : Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI, et le projet vLLM développé au Sky Computing Lab à UC Berkeley.


