

Anthropic lance une IA Claude 3.7 Sonnet plus intelligente, capable de jouer à Pokémon Red comme un pro prometteur
Anthropic a lancé Claude 3.7 Sonnet, son dernier chatbot IA doté de compétences avancées en matière de codage et de réflexion profonde pour résoudre des invites et des tâches de programmation complexes en utilisant une fenêtre de jetons plus grande de 128K.
À l'instar d'autres modèles d'IA à langage étendu récemment lancés par OpenAI et xAI, l'ajout de la réflexion approfondie permet à la dernière IA d'Anthropic de prendre plus de temps pour résoudre des problèmes difficiles avant de répondre.
Cela a permis à Claude de passer d'un statut de traînard à celui d'une des IA les plus performantes sur de nombreux tests difficiles tels que le test GPQA de niveau doctoral https://arxiv.org/abs/2311.12022. Néanmoins, la mise à jour ne signifie pas que la version 3.7 est la meilleure IA au monde, puisqu'elle n'occupe pas la première place dans certains tests de référence par rapport à d'autres modèles très performants.
Néanmoins, Claude peut avancer beaucoup plus loin dans des jeux comme Pokémon Red que les modèles précédents de l'entreprise. Les programmeurs bénéficient également de sa capacité améliorée à résoudre des problèmes logiciels réels et à créer du code. Un aperçu limité de Claude Code donne accès à un agent qui collabore avec le programmeur pour éditer, tester et mettre à jour des bases de code complexes sur GitHub, ce qui permet aux programmeurs de gagner beaucoup de temps.
Une IA plus intelligente est potentiellement plus dangereuse. Claude 3.7 Sonnet a répondu trois fois plus souvent que Claude 3.5 à des questions enfreignant les politiques d'Anthropic lors des évaluations internes de sécurité, bien qu'à un taux globalement faible (0,6 % du temps). L'IA a également été capable d'infecter un réseau test d'ordinateurs et d'exfiltrer des données grâce à des méthodes de cyberattaque incluant la réécriture de code. La version publique de Claude a mis en place des mesures de protection pour empêcher ce type d'utilisation.
Les lecteurs peuvent utiliser les fonctionnalités de base de Claude 3.7 Sonnet gratuitement aujourd'hui, tandis que les fonctionnalités avancées telles que le raisonnement étendu nécessitent un abonnement payant.

Source(s)
Claude 3.7 Sonnet et code Claude
24 février, 2025
5 minutes de lecture
Une illustration de Claude pensant étape par étape
Aujourd'hui, nous annonçons Claude 3.7 Sonnet1, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi-instantanées ou des raisonnements détaillés, étape par étape, qui sont rendus visibles à l'utilisateur. Les utilisateurs de l'API peuvent également contrôler finement la durée de réflexion du modèle.
Claude 3.7 Sonnet présente des améliorations particulièrement importantes en matière de codage et de développement web frontal. En plus du modèle, nous introduisons également un outil de ligne de commande pour le codage agentique, Claude Code. Claude Code est disponible en avant-première de recherche limitée, et permet aux développeurs de déléguer des tâches d'ingénierie substantielles à Claude directement à partir de leur terminal.
Écran montrant l'intégration de Claude Code
Claude 3.7 Sonnet est maintenant disponible sur tous les plans Claude - y compris Free, Pro, Team, et Enterprise - ainsi que l'API Anthropic, Amazon Bedrock, et Google Cloud's Vertex AI. Le mode de réflexion étendu est disponible sur toutes les surfaces à l'exception du niveau Claude gratuit.
En mode de réflexion standard et étendu, Claude 3.7 Sonnet a le même prix que ses prédécesseurs : 3 $ par million de jetons d'entrée et 15 $ par million de jetons de sortie, ce qui inclut les jetons de réflexion.
Claude 3.7 Sonnet : Le raisonnement frontalier rendu pratique
Nous avons développé Claude 3.7 Sonnet avec une philosophie différente des autres modèles de raisonnement sur le marché. Tout comme les humains utilisent un seul cerveau pour les réponses rapides et la réflexion profonde, nous pensons que le raisonnement devrait être une capacité intégrée des modèles de frontière plutôt qu'un modèle entièrement séparé. Cette approche unifiée crée également une expérience plus transparente pour les utilisateurs.
Claude 3.7 Sonnet incarne cette philosophie de plusieurs façons. Tout d'abord, Claude 3.7 Sonnet est à la fois un LLM ordinaire et un modèle de raisonnement : vous pouvez choisir quand vous voulez que le modèle réponde normalement et quand vous voulez qu'il réfléchisse plus longtemps avant de répondre. En mode standard, Claude 3.7 Sonnet représente une version améliorée de Claude 3.5 Sonnet. En mode de réflexion prolongée, il réfléchit avant de répondre, ce qui améliore ses performances en mathématiques, physique, suivi d'instructions, codage et bien d'autres tâches. Nous constatons généralement que l'incitation au modèle fonctionne de la même manière dans les deux modes.
Deuxièmement, lorsque vous utilisez Claude 3.7 Sonnet à travers l'API, les utilisateurs peuvent également contrôler le budget de réflexion : vous pouvez dire à Claude de réfléchir pendant un maximum de N tokens, pour n'importe quelle valeur de N jusqu'à sa limite de 128K tokens. Cela vous permet de faire un compromis entre la vitesse (et le coût) et la qualité de la réponse.
Troisièmement, en développant nos modèles de raisonnement, nous avons optimisé un peu moins pour les problèmes de concours de mathématiques et d'informatique, et nous nous sommes plutôt concentrés sur des tâches du monde réel qui reflètent mieux la façon dont les entreprises utilisent réellement les LLM.
Les premiers tests ont démontré la supériorité de Claude en matière de capacités de codage dans tous les domaines : Cursor a noté que Claude est une fois de plus le meilleur de sa catégorie pour les tâches de codage dans le monde réel, avec des améliorations significatives dans des domaines allant de la gestion de bases de code complexes à l'utilisation d'outils avancés. Cognition l'a trouvé bien meilleur que n'importe quel autre modèle pour planifier les changements de code et gérer les mises à jour de l'ensemble de la pile. Vercel a souligné la précision exceptionnelle de Claude pour les flux de travail complexes des agents, tandis que Replit a déployé Claude avec succès pour construire des applications web et des tableaux de bord sophistiqués à partir de zéro, là où d'autres modèles achoppent. Dans les évaluations de Canva, Claude a toujours produit du code prêt à la production avec un goût du design supérieur et une réduction drastique des erreurs.
Diagramme à barres montrant que Claude 3.7 Sonnet est l'état de l'art pour le banc d'essai SWE Vérifié
Claude 3.7 Sonnet atteint des performances de pointe sur SWE-bench Verified, qui évalue la capacité des modèles d'IA à résoudre des problèmes logiciels réels. Voir l'annexe pour plus d'informations sur l'échafaudage.
Diagramme à barres montrant que Claude 3.7 Sonnet est à l'état de l'art pour TAU-bench
Claude 3.7 Sonnet atteint des performances de pointe sur TAU-bench, un cadre qui teste les agents d'intelligence artificielle sur des tâches complexes du monde réel avec des interactions entre l'utilisateur et l'outil. Voir l'annexe pour plus d'informations sur l'échafaudage.
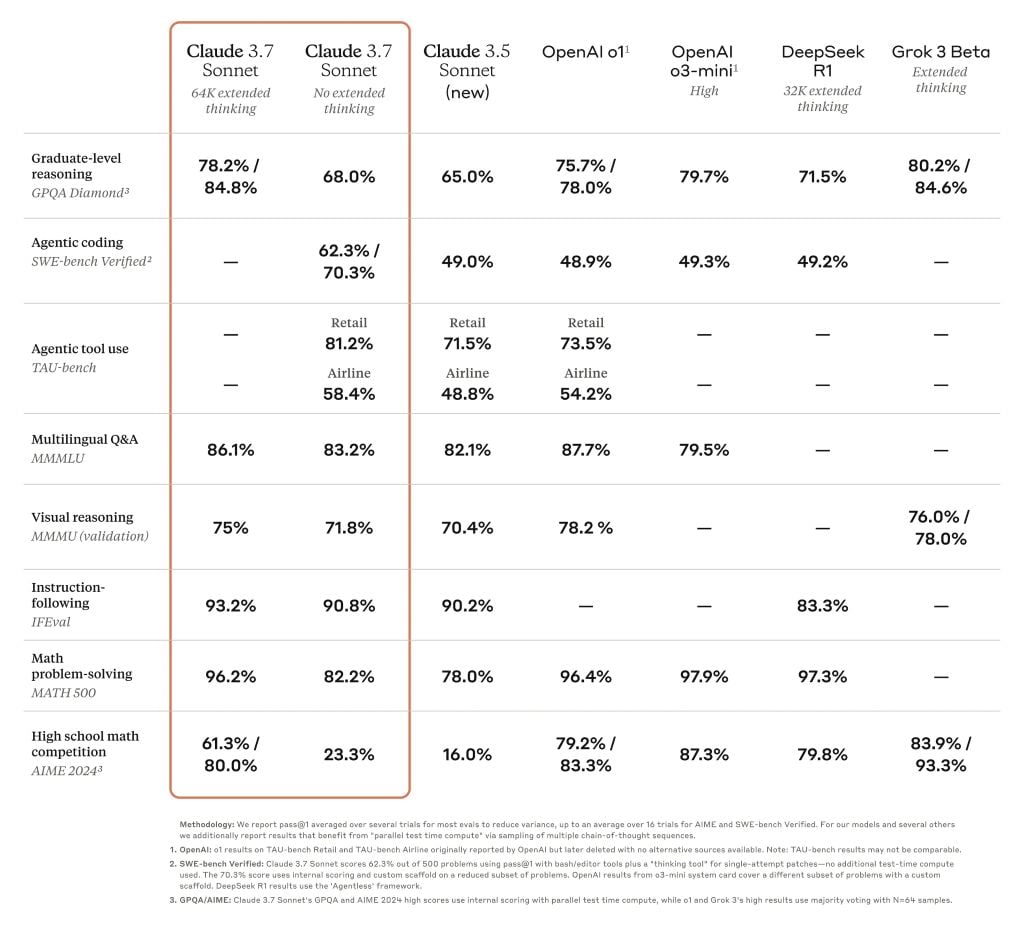
Tableau de benchmark comparant les modèles de raisonnement à la frontière
Claude 3.7 Sonnet excelle dans le suivi des instructions, le raisonnement général, les capacités multimodales et le codage agentique, le raisonnement étendu apportant une amélioration notable en mathématiques et en sciences. Au-delà des benchmarks traditionnels, il a même surpassé tous les modèles précédents dans nos tests de jeu Pokémon.
Code Claude
Depuis juin 2024, Sonnet est le modèle préféré des développeurs du monde entier. Aujourd'hui, nous donnons encore plus de pouvoir aux développeurs en introduisant Claude Code - notre premier outil de codage agentique - dans un aperçu de recherche limité.
Claude Code est un collaborateur actif qui peut rechercher et lire du code, éditer des fichiers, écrire et exécuter des tests, livrer et pousser du code sur GitHub, et utiliser des outils de ligne de commande - en vous gardant dans la boucle à chaque étape.
Claude Code est un produit précoce mais il est déjà devenu indispensable pour notre équipe, en particulier pour le développement piloté par les tests, le débogage de problèmes complexes et le remaniement à grande échelle. Lors des premiers tests, Claude Code a accompli en une seule fois des tâches qui auraient normalement nécessité plus de 45 minutes de travail manuel, réduisant ainsi le temps de développement et les coûts indirects.
Dans les semaines à venir, nous prévoyons de l'améliorer continuellement sur la base de notre utilisation : amélioration de la fiabilité des appels d'outils, ajout d'un support pour les commandes de longue durée, amélioration du rendu dans l'application, et développement de la compréhension de ses propres capacités par Claude.
Notre objectif avec Claude Code est de mieux comprendre comment les développeurs utilisent Claude pour coder afin d'informer les futures améliorations du modèle. En rejoignant cet aperçu, vous aurez accès aux mêmes outils puissants que nous utilisons pour construire et améliorer Claude, et vos commentaires façonneront directement son avenir.
Travailler avec Claude sur votre base de code
Nous avons également amélioré l'expérience de codage sur Claude.ai. Notre intégration GitHub est maintenant disponible sur tous les plans de Claude - permettant aux développeurs de connecter leurs dépôts de code directement à Claude.
Claude 3.7 Sonnet est notre meilleur modèle de codage à ce jour. Avec une meilleure compréhension de vos projets personnels, professionnels et open source, il devient un partenaire plus puissant pour corriger les bugs, développer des fonctionnalités et construire de la documentation sur vos projets GitHub les plus importants.
Construire de manière responsable
Nous avons mené des tests et des évaluations approfondis de Claude 3.7 Sonnet, en travaillant avec des experts externes pour nous assurer qu'il répond à nos normes de sécurité, de sûreté et de fiabilité. Claude 3.7 Sonnet fait également des distinctions plus nuancées entre les requêtes nuisibles et bénignes, réduisant les refus inutiles de 45% par rapport à son prédécesseur.
La carte système de cette version couvre les nouveaux résultats de sécurité dans plusieurs catégories, fournissant une ventilation détaillée de nos évaluations de la politique de mise à l'échelle responsable que d'autres laboratoires d'IA et chercheurs peuvent appliquer à leur travail. Elle explique comment nous évaluons ces vulnérabilités et comment nous formons Claude à y résister et à les atténuer. En outre, elle examine les avantages potentiels des modèles de raisonnement en matière de sécurité : la capacité de comprendre comment les modèles prennent des décisions, et si le raisonnement du modèle est véritablement digne de confiance et fiable. Pour en savoir plus, lisez la fiche complète du système.
Perspectives d'avenir
Claude 3.7 Sonnet et Claude Code marquent une étape importante vers des systèmes d'IA qui peuvent réellement augmenter les capacités humaines. Avec leur capacité à raisonner en profondeur, à travailler de manière autonome et à collaborer efficacement, ils nous rapprochent d'un avenir où l'IA enrichit et élargit ce que l'homme peut accomplir.
Chronologie des étapes montrant la progression de Claude, de l'assistant au pionnier
Nous sommes impatients de vous voir explorer ces nouvelles capacités et de voir ce que vous allez créer avec elles. Comme toujours, vos commentaires sont les bienvenus, car nous continuons à améliorer et à faire évoluer nos modèles.
Annexe
1 Leçon apprise sur la dénomination.
Sources de données Eval
Grok
Gemini 2 Pro
o1 et o3-mini
Supplémentaire o1
o1 TAU-bench
Supplémentaire o3-mini
Deepseek R1
Banc TAU
Informations sur l'échafaudage
Les scores ont été obtenus grâce à un ajout à la politique de l'agent de la compagnie aérienne demandant à Claude de mieux utiliser un outil de "planification", dans lequel le modèle est encouragé à écrire ses pensées au fur et à mesure qu'il résout le problème, contrairement à notre mode de pensée habituel, pendant les trajectoires multi-tours, afin de tirer le meilleur parti de ses capacités de raisonnement. Pour tenir compte des étapes supplémentaires que Claude doit franchir en réfléchissant davantage, le nombre maximal d'étapes (compté par le nombre de modèles terminés) a été augmenté de 30 à 100 (la plupart des trajectoires se sont terminées en dessous de 30 étapes et une seule trajectoire a dépassé les 50 étapes).
En outre, le score TAU-bench pour Claude 3.5 Sonnet (nouveau) diffère de ce que nous avons initialement rapporté lors de la publication en raison de petites améliorations apportées à l'ensemble de données depuis lors. Nous avons refait une analyse sur le jeu de données mis à jour pour une comparaison plus précise avec Claude 3.7 Sonnet.
Banc SWE vérifié
Informations sur l'échafaudage
Il existe de nombreuses approches pour résoudre des tâches agentiques ouvertes comme SWE-bench. Certaines approches déchargent une grande partie de la complexité du choix des fichiers à examiner ou à modifier et des tests à exécuter vers des logiciels plus traditionnels, laissant le modèle de langage central générer du code à des endroits prédéfinis, ou choisir parmi un ensemble plus limité d'actions. Agentless (Xia et al., 2024) est un cadre populaire utilisé dans l'évaluation du modèle R1 de Deepseek et d'autres modèles qui complète un agent avec des mécanismes de récupération de fichiers basés sur l'invite et l'intégration, la localisation de correctifs et l'échantillonnage de rejet du meilleur des 40 par rapport aux tests de régression. D'autres échafaudages (par exemple Aide) complètent les modèles avec des calculs supplémentaires pendant le temps de test sous la forme de tentatives, de meilleurs résultats ou de recherche arborescente de Monte Carlo (MCTS).
Pour Claude 3.7 Sonnet et Claude 3.5 Sonnet (nouveau), nous utilisons une approche beaucoup plus simple avec un échafaudage minimal, où le modèle décide des commandes à exécuter et des fichiers à éditer en une seule session. Notre principal résultat pass@1 "sans réflexion approfondie" équipe simplement le modèle des deux outils décrits ici - un outil bash et un outil d'édition de fichiers qui fonctionne par remplacement de chaînes - ainsi que de l'"outil de planification" mentionné ci-dessus dans les résultats de notre banc d'essai TAU. En raison des limitations de l'infrastructure, seuls 489/500 problèmes peuvent être résolus sur notre infrastructure interne (c'est-à-dire que la solution en or passe les tests). Pour notre score vanille pass@1, nous comptons les 11 problèmes insolubles comme des échecs afin de maintenir la parité avec le classement officiel. Par souci de transparence, nous publions séparément les cas de test qui n'ont pas fonctionné sur notre infrastructure.
Pour notre chiffre de "calcul élevé", nous adoptons une complexité supplémentaire et un calcul parallèle du temps de test comme suit :
Nous échantillonnons plusieurs tentatives parallèles avec l'échafaudage ci-dessus
Nous écartons les correctifs qui cassent les tests de régression visibles dans le référentiel, de manière similaire à l'approche d'échantillonnage de rejet adoptée par Agentless ; notez qu'aucune information sur les tests cachés n'est utilisée.
Nous classons ensuite les tentatives restantes à l'aide d'un modèle de notation similaire à nos résultats sur GPQA et AIME décrits dans notre article de recherche et choisissons la meilleure pour la soumission.
Il en résulte un score de 70,3% sur le sous-ensemble de n=489 tâches vérifiées qui fonctionnent sur notre infrastructure. Sans cet échafaudage, Claude 3.7 Sonnet obtient 63,7% sur le banc SWE vérifié en utilisant ce même sous-ensemble. Les 11 cas de test exclus qui étaient incompatibles avec notre infrastructure interne sont les suivants :
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711









